Introduction
Dans la continuité des articles sur les nouveautés apportées par la BI 4.2 SP5 (vous pouvez également retrouver les articles sur les nouveautés Web Intelligence & Administration), nous allons aborder ici les nouveautés de l’outil de conception d’information (Information Design Tool = IDT).
Parmi ces nouveautés, beaucoup permettent de simplifier la création et la maintenance de vos univers en améliorant l’interface de l’outil.
Nouveauté importante de la BI 4.2 SP3, les BI Sets ont encore été enrichis dans cette version SP5 de nouvelles fonctionnalités, rendant leur attrait encore plus important pour le développement de vos univers.
Découvrons sans plus attendre ces nouvelles fonctionnalités de l’outil IDT de la BI 4.2 SP5 !
Gestion des contextes simplifiée
Il n’est plus nécessaire de cliquer sur le bouton « Modifier » pour éditer un contexte : un double-clic sur une jointure permet en effet d’en modifier directement le statut. De plus, la multi-sélection est opérationnelle pour permettre d’inclure, d’exclure ou d’ignorer les jointures sélectionnées de manière rapide et en minimisant les risques d’erreur.
Le statut des jointures est donc maintenant beaucoup plus visible et surtout directement sélectionnable.
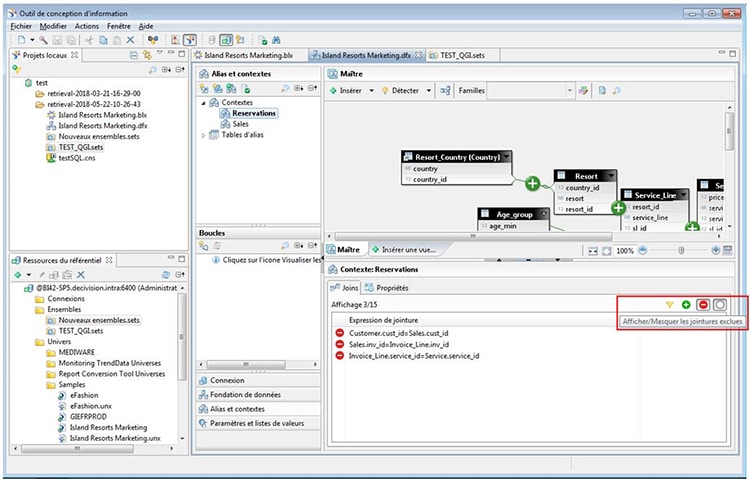
Notre avis : Cette amélioration va simplifier la mise en place des contextes, on retrouve un fonctionnement similaire à l’ancien outil Designer.
Organisation automatique des objets
Des tris croissants ou décroissants sont maintenant possibles dans les options des dossiers : cette option permet de classer rapidement les objets d’un dossier ou d’un sous-dossier.
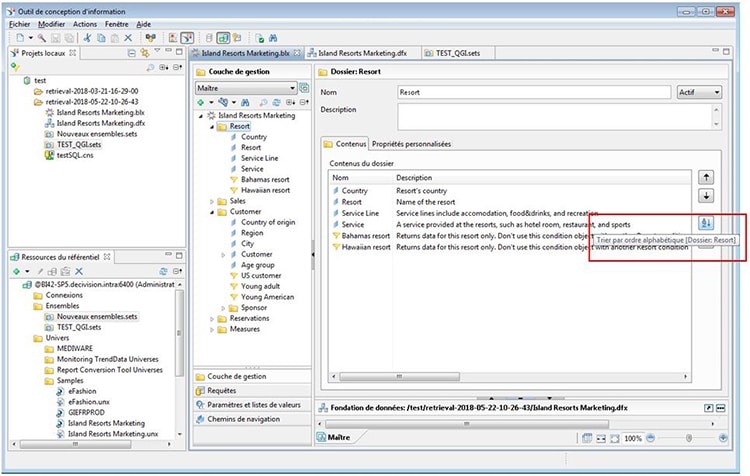
Ces options ont également été incluses au niveau du dossier racine, rendant ces tris possibles directement dans toute l’arborescence de votre univers !
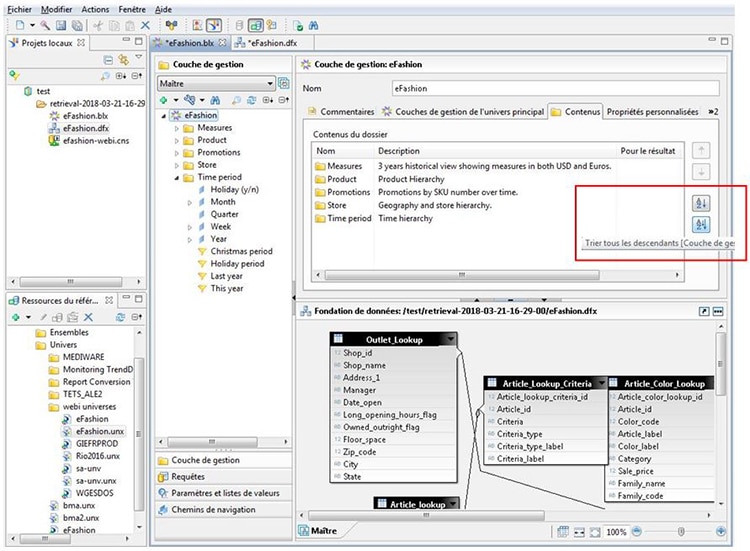
Dans les préférences de la couche de la gestion, vous pouvez sélectionner l’option qui correspond le mieux à vos besoins pour les objets, les dossiers, les sous-dossiers, … :
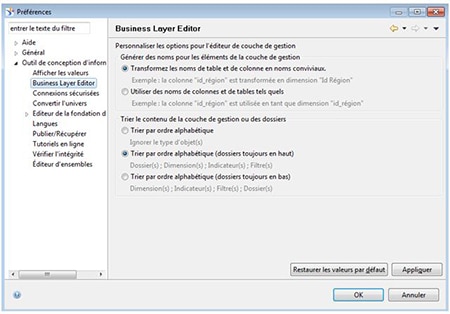
Seul bémol sur cette nouveauté, les objets ajoutés par la suite dans l’univers ne sont pas triés automatiquement.
Notre avis : Cette fonctionnalité va permettre de créer et d’organiser l‘arborescence des objets d’un univers plus rapidement, mais nous savons que dans beaucoup de cas pratiques les objets sont organisés fonctionnellement parlant et non par ordre alphabétique.
Affichage SQL amélioré
Dans l’éditeur de formule, vous pouvez maintenant utiliser le bouton « Afficher SQL » pour permettre l’affichage détaillé des objets utilisés dans les clauses @select ou @where.
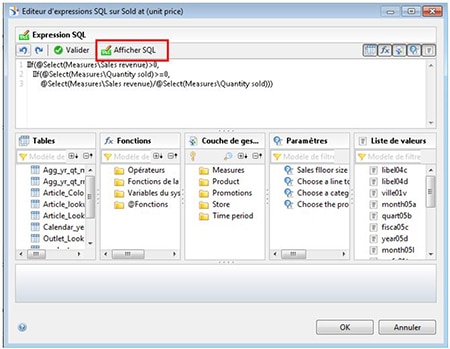
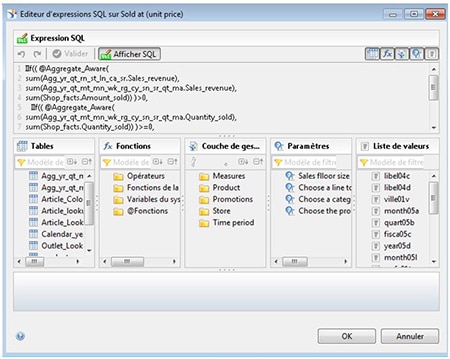
Notre avis : Cette petite aide sera bien utile lorsque vous avez créé plusieurs objets permettant d’encapsuler la complexité, on pourra à tout moment vérifier la source de la formule.
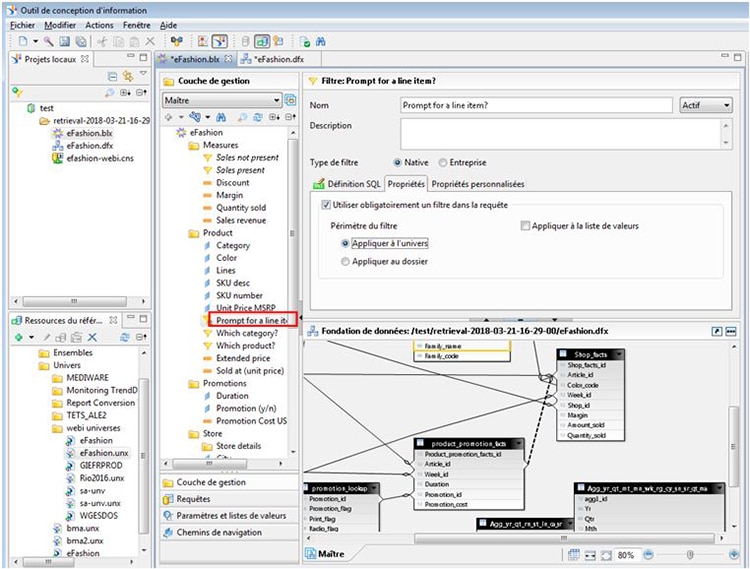
Filtres sur l’univers
Dans la liste des objets, les filtres appliqués à l’univers apparaissent maintenant différemment pour permettre de les identifier directement.
SAP propose maintenant la possibilité de créer des listes de valeurs à partir de tables dérivées. Il est nécessaire dans ce cas d’utiliser la fonction « @DerivedTable ».
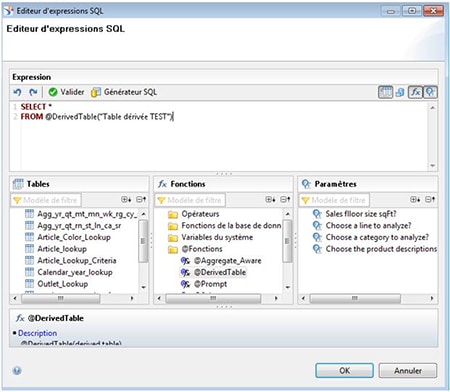
Cette fonctionnalité a aussi été incluse dans les BI 4.2 SP3 Patch 8 et SP4 Patch 2.
Notre avis : La possibilité de créer des listes de valeurs à partir de table dérivée est très utile lorsque vous souhaitez personnaliser vos listes de valeur.
Réparation des références
Cette option peut être utilisée pour réparer la couche sémantique lorsque la fondation de données a été modifiée. Typiquement, en cas de suppression d’une table d’alias ou d’une table dérivée, cette commande permet de remapper les objets alors invalides (y compris les listes de valeurs, les prompts…) avec la nouvelle référence, à condition que le même nom ait été utilisé.
Notre avis : Cette option va nous permettre de réparer rapidement un univers lorsque la fondation de données a été modifiée. Auparavant, cette étape pouvait s’avérer longue et chronophage si la couche de gestion contenait beaucoup d’objets. Encore une option qui nous simplifie la maintenance des univers.
Gestion des univers
Il est désormais possible de déverrouiller un univers aussi bien par l’utilisateur qui a posé le verrou que par le compte « Administrator ».
Notre avis : Cette option va faciliter l’administration de la plateforme, lorsque les utilisateurs verrouillent un univers par erreur.
Description de la session
A la création ou à l’ouverture d’une session, vous pouvez maintenant ajouter une description via un champ dédié. Cette action permettra la génération d’une info-bulle affichant la description directement sur la session.
Extraction d’un univers
La génération du nom de dossier lors de l’extraction d’un univers du référentiel peut maintenant être contrôlée en choisissant soit :
- retrieval-<date-time> (option par défaut)
- <universename>-<date-time> (nouvelle option disponible)
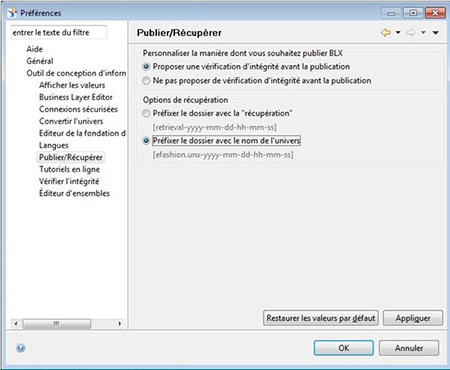
Notre avis : Idéal pour mieux s’y retrouver dans vos projets !
BI SETS
Les BI Sets sont une fonctionnalité très puissante qui permet de créer des filtres complexes à partir de plusieurs ensembles de données.
Ces filtres permettent de mettre à disposition des utilisateurs des populations cibles correspondant à la combinaison de plusieurs critères. Les utilisateurs pourront par la suite utiliser ces populations pour leurs besoins dans leurs requêtes.
Nous réaliserons prochainement un article dédié à cette fonctionnalité, elle peut être en effet difficile à appréhender.
En ce qui concerne le SP5, les BI Sets ont connu différentes évolutions, notamment :
- Utilisation des “Composite Keys”
Les sujets (accessibles via la gestion des conteneurs d’ensemble) peuvent maintenant être créés sur des clés composites : lorsque vous sélectionnez la dimension associée, vous pouvez choisir plusieurs objets comme clés. Très utile lorsqu’un sujet concerne plusieurs dimensions.
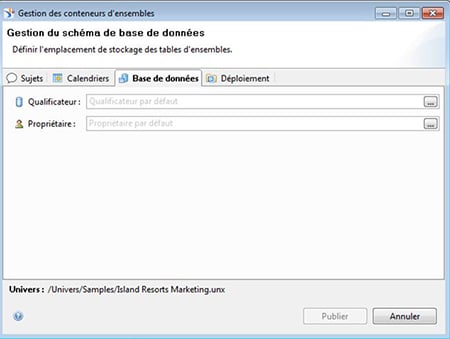
- Utiliser un schéma de bases de données
Lors du paramétrage des conteneurs d’ensemble, vous pouvez paramétrer le schéma de bases de données à utiliser (qualificateur & propriétaire). Le set ainsi paramétré pourra donc être dédié à un schéma en particulier.
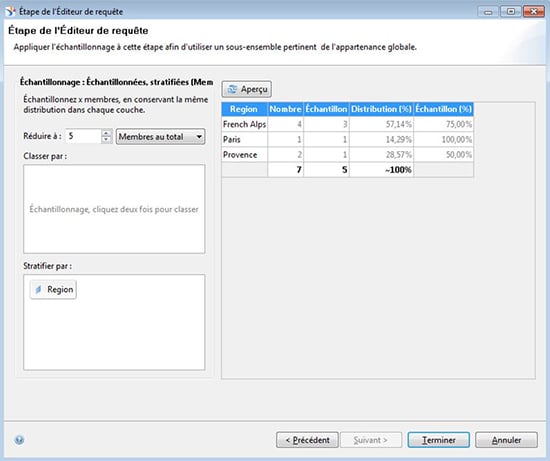
- Echantillonnage
Lors de la création d’un set, vous pouvez utiliser seulement un échantillon de votre base de données.
La taille de cet échantillon peut être définie soit en pourcentage soit en nombre.
Vous pouvez générer aléatoirement les membres de votre filtre (option par défaut) ou bien utiliser les deux critères suivants :
- Classement (par un ou plusieurs objets)
- Stratification : pour garantir, en fonction de vos critères, que la distribution de l’échantillon sera équivalente à celle de la base de données, en fonction de l’objet utilisé pour la stratification
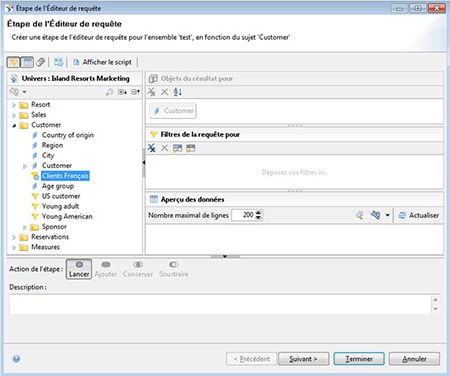
- Utiliser des Sets comme filtres pour la définition d’autres Sets
Lors de la définition d’une nouvelle étape dans le panneau de configuration de requêtes, vous pouvez utiliser d’autres sets déjà définis comme filtres. Très utile dans le cas de sous-requêtes.
- « Frozen Sets »
Cette option permet d’éviter qu’un set soit modifié : il est par exemple possible de figer un set dans le temps. Seul le nom ou la description pourront être modifiés dans ce cas.
- Temporal Sets
De nouvelles options sont disponibles comme par exemple la possibilité d’ajouter une limite temporelle pour ne conserver que les derniers enregistrements, ou bien de ne travailler que sur la période courante.
Notre avis : Les BI SETS sont très puissants, ils permettent de créer et de manipuler des ensembles de données afin de réaliser des filtres complexes. Cette fonctionnalité a un gros avantage, elle nous permet d’encapsuler dans la couche Univers cette complexité, afin de fournir à l’utilisateur des filtres complexes qui peuvent être utilisés simplement.
Cette fonctionnalité est peu connue, mais permet beaucoup de possibilités, nous y reviendrons prochainement dans un article dédié.
Sources de données supportées
De nouvelles sources de données sont maintenant supportées (liste non exhaustive) :
- Apache Hive 2.0, 2.1
- Cloudera Impala 2.7
- HP Vertica 8
- DB2 for LUW 11.
- DB2 for zOS 12
- Excel 2016, Access 2016
- Oracle 12c R2
- Oracle Exadata 12
- PostgreSQL 9.6
- Hortonworks 2.5
- MaxDB 7.9
- Teradata 16
Attention certaines sources ne sont plus supportées !
- Apache Hive -> 0.13
- HP Vertica 6.1
- DB2 for i 6.1
- DB2 for LUW 10.0
- Excel 2007
- SQL Server 2008 R2
- PostgreSQL 9.2
- SQLAnywhere 12
- Sybase IQ 15.4
- Teradata 14
La liste complète des sources supportées est consultable dans la PAM « Product Availability Matrix » sur le site de SAP, nous pouvons aussi vous la fournir au besoin.
CONCLUSION DE L’EXPERT
Dans ce Service Pack, SAP renforce encore l’attractivité de l’outil IDT, certaines fonctionnalités peu ergonomiques ont été mises à jour et d’autres très pratiques apparaissent.
Notons qu’aujourd’hui SAP propose des nouveautés exclusivement sur l’outil IDT, il n’y a quasiment plus d’amélioration sur l’outil UDT (anciennement Designer)
Ces fonctionnalités de plus en plus nombreuses (et intuitives) sur IDT nous renforcent dans nos préconisations de développer tout nouvel univers avec cet outil plutôt qu’avec l’ancien Designer (UDT).
Ce sont encore des raisons supplémentaires pour franchir le pas vers les univers « unx » !



