Introduction
Les entreprises ont besoin de fiabiliser de plus en plus leurs données. En effet, il est important d’avoir un gage de qualité sur les données critiques. Toutefois, cela n’est pas toujours suffisant : certaines entreprises souhaitent maintenant gérer de manière proactive la qualité de leurs données tout en analysant leur impact dans leur utilisation.
L’outil Information Steward, présent dans la suite des produits SAP, peut jouer ce rôle en aidant les entreprise à mieux comprendre, évaluer, fiabiliser et améliorer leurs données afin de leur donner un atout stratégique. Il permet également d’éliminer les risques dans les opérations et les analyses des données.
Présentation
Les objectifs principaux de cet outil sont les suivants :
- Evaluer en permanence la fiabilité des données
- Déterminer l’impact et les ROI des données en termes de qualité
- Faire des données critiques un atout stratégique dans l’entreprise
Information Steward est une solution qui propose :
- une gestion des politiques d’information pour définir la stratégie de gouvernance
- un glossaire des termes métier pour maintenir les concepts standards
- une gestion des métadonnées pour une vue intégrée des métadonnées
- une analyse de la hiérarchie des données et de l’impact des modifications et de la qualité
- un profilage des données pour une évaluation rapide de celles-ci
- une validation des données pour améliorer la qualité des normes
- une visualisation des erreurs, de la qualité des données, et de l’analyse d’impact grâce à des tableaux de bord
SAP Information Steward propose un environnement unique pour découvrir, évaluer, définir, contrôler et améliorer la qualité des données critiques de l’entreprise à travers plusieurs modules :
- Générateur de packages de nettoyage : offre la possibilité de créer des packages de nettoyage pour analyser, nettoyer, améliorer et normaliser les données.
- Data Insight : permet de créer et d’appliquer des règles de validation afin de surveiller la qualité des données à travers des cartes de performance. Il est ainsi possible de contrôler les données selon des critères personnalisés.
- Gestion des métadonnées : à travers une bibliothèque des métadonnées dans l’environnement système, il est ainsi possible d’analyser et de comprendre les relations entre les données de l’entreprise.
- Métapédia : permet de définir les termes fonctionnels pour les données et d’organiser les termes en catégories.
- Vérification des correspondances : contrôle l’automatisation des correspondances et corrige si nécessaire les incohérences. Il maintient ainsi une liste des enregistrements dans l’onglet « Ma liste de travail » qui implique les actions des réviseurs pour les décisions de correspondance.
- Data Quality Advisor : intégré directement à lnformation Steward, il permet d’évaluer rapidement les problèmes de qualité des données afin de proposer une solution adéquate et optimisée. Il propose la découverte du type de contenu, le conseil de validation et de nettoyage de données.
Dans la suite de cet article, nous verrons plus en détails certains de ces différents modules, complémentaires les uns aux autres.
Accès et ressources
L’URL d’accès à la console de SAP Information Steward est :
http://[NOM_SERVEUR]:8080/BOE/InfoStewardApp ou http://[NOM_SERVEUR]:8080/BOE/InfoSteward
Une licence spécifique est indispensable pour l’utilisation de ce module.
Information Steward dépend de la plateforme SAP BusinessObjects / Information Platform Services (IPS) pour la sécurité et la gestion des utilisateurs (tout comme Data Services). Il faut donc faire attention à la compatibilité entre les versions (cf. PAM SAP).
Générateur de packages de nettoyage des données
Comme évoqué précédemment, le module « Générateur de packages de nettoyage des données » (Cleansing Package Builder) vous offre la possibilité de créer des packages personnalisés afin d’analyser, de nettoyer, d’améliorer et de normaliser les données. Ces packages pourront alors être utilisés par la suite directement dans l’outil SAP Data Services (Designer) au sein même de vos traitements. Les données en entrée seront alors soumises aux règles définies dans vos packages afin de les rendre plus propres, plus fiables et normées.
Pour créer un package de nettoyage des données, il faut vous connecter à la console d’Information Steward, puis aller sur l’onglet « Générateur de packages de nettoyage des données ».
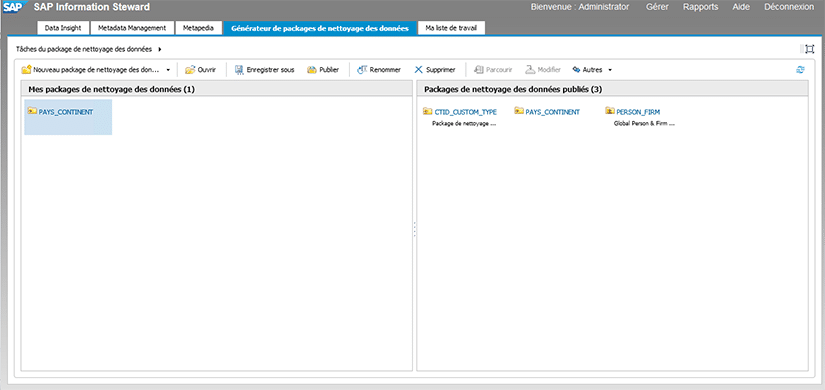
Un package se base sur un fichier (csv, txt…) contenant un jeu de données d’exemple. En effet, les règles que vous allez définir dans votre package de nettoyage vont être appliquées sur ce jeu de données. Il faut donc que ce jeu de données soit représentatif des données qui seront traitées par la suite dans SAP Data Services.
Dans notre exemple, nous allons utiliser un fichier csv avec le contenu suivant :
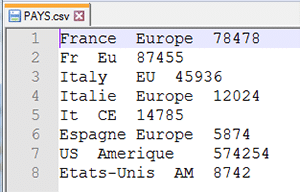
Les règles que nous allons définir vont porter sur les noms des pays et des continents. Ces noms peuvent être orthographiés de différentes manières (langue, faute de frappe, abréviation…). Les règles que nous allons appliquer consisteront à harmoniser l’orthographe de ces noms. En d’autres termes, nous allons associer les différentes variantes possibles à un nom unique.
Pour l’Italie, nous allons appliquer la règle suivante :
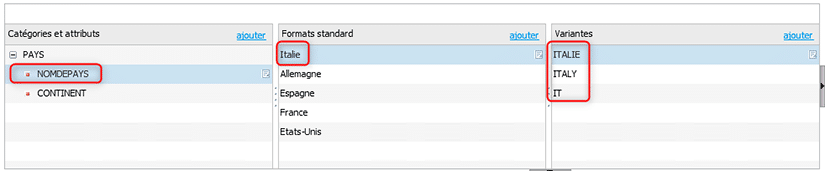
De la même manière, voici la règle appliquée pour le continent « Europe » :
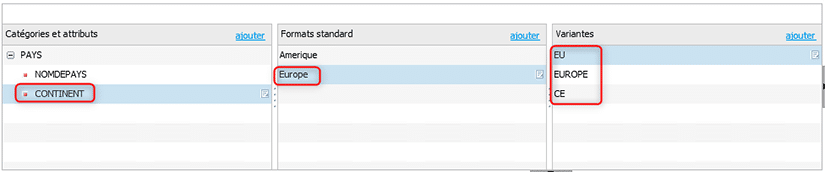
Voici à présent le résultat de l’application de ces règles d’harmonisation sur l’ensemble du jeu de données :
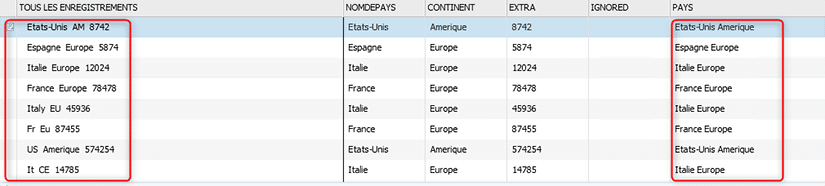
Nous avons bien en sortie un nom de pays et un nom de continent unique.
Une fois ce package créé, il faut le publier sur le référentiel, pour ensuite obtenir l’ATL Data Services de ce package de nettoyage des données.
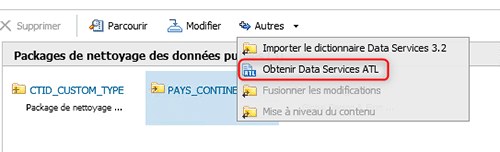
Nous obtenons alors un script, qu’il faut récupérer et copier dans un fichier texte, puis enregistrer au format « ATL ».
Il faut maintenant ouvrir l’outil SAP Data Services puis importer le fichier ATL précédemment créé.
Notre package de nettoyage de données est maintenant disponible dans la bibliothèque des transformations « Data_Cleanse » de notre référentiel.
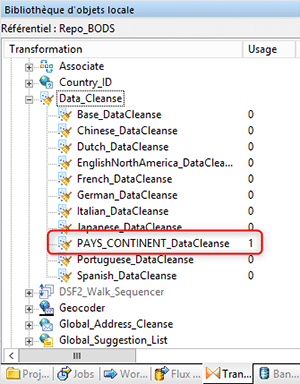
Voici un exemple d’utilisation de notre package de nettoyage de données dans Data Services :
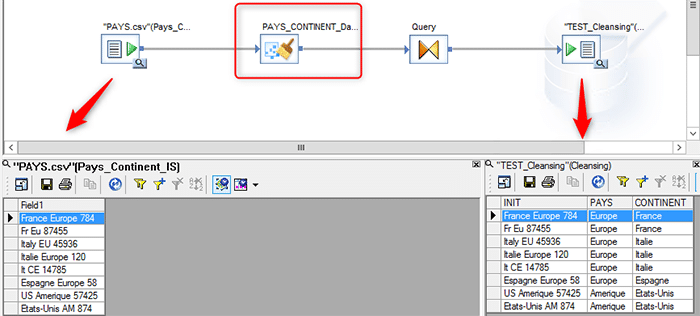
Data Insight
Ce module permet de créer et d’appliquer des règles de validation afin de surveiller la qualité des données à travers des cartes de performance. Il est ainsi possible de contrôler les données selon des critères personnalisés. Afin de gérer l’analyse de la qualité des données et le profilage, nous devons utiliser la CMC (Central Management Console).
Nous allons montrer ci-dessous un exemple permettant de calculer le score de fiabilité de notre jeu de données.
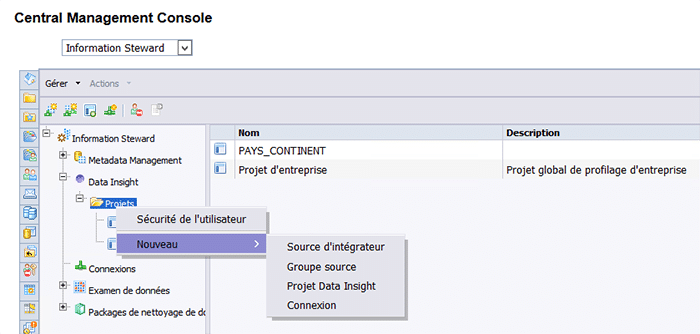
Création d’un projet Data Insight
La première étape consiste à créer un projet Data Insight. Pour cela, il faut aller dans le module « Information steward » de la CMC.
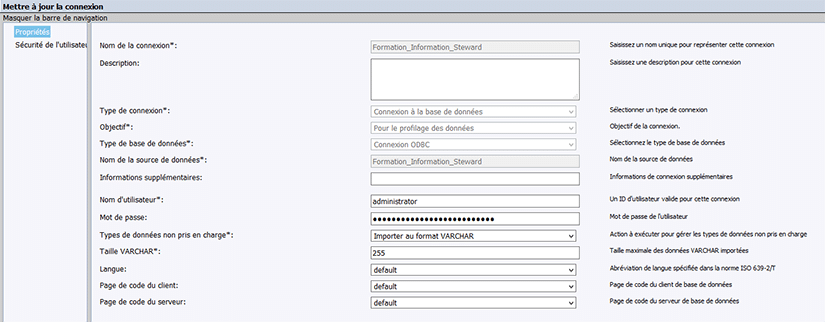
Création d’une connexion
Il faut ensuite créer une connexion (de préférence ODBC). Cette connexion doit pointer vers la base de données que l’on souhaite qualifier par la suite dans l’outil Information Steward. Cette base de données pointe le plus souvent vers un entrepôt de données.
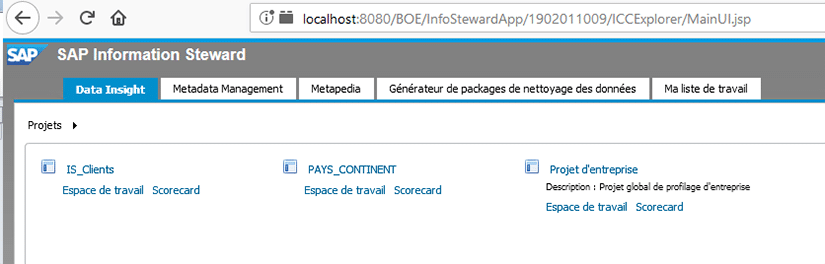
Connexion au module « Data Insight » d’Information Steward
Une fois connecté à la console d’administration d’Information Steward, il faut aller ensuite dans le module Data Insight et ouvrir le projet précédemment créé (via la CMC).
Il faut ensuite ajouter une source de données dans l’espace de travail, qui peut être de type fichier (xlsx, csv, txt…) ou bien une table d’une base de données.
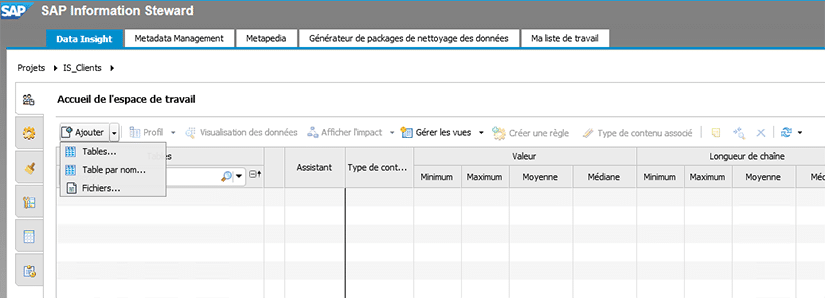
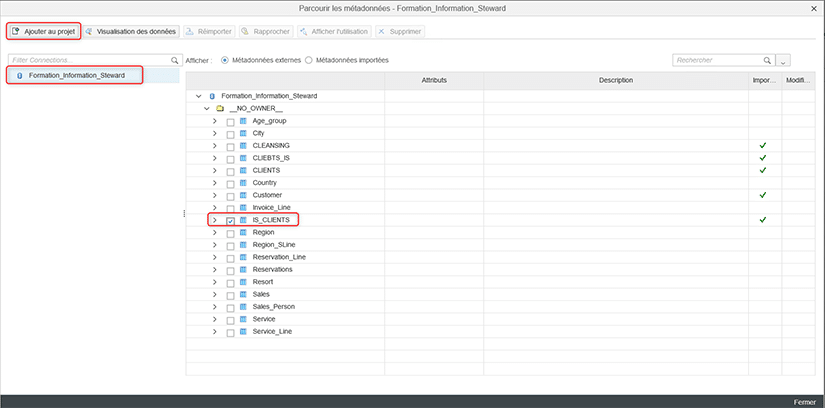
Dans notre exemple, nous décidons d’ajouter la table IS_CLIENTS présente dans la base de données associée à notre connexion définie au préalable dans la CMC.
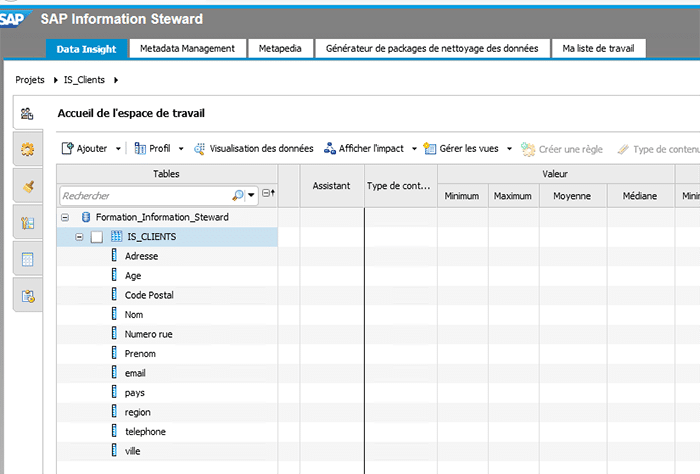
Une fois ajoutée, nous pouvons voir le détail de la table dans l’espace de travail.
Création des règles
Un des objectifs du module « Data Insight » est de qualifier la donnée. Pour cela, il faut créer des règles avec des critères bien spécifiques. Pour cela, il faut aller dans l’onglet « Règles » sur le bandeau vertical sur la gauche.
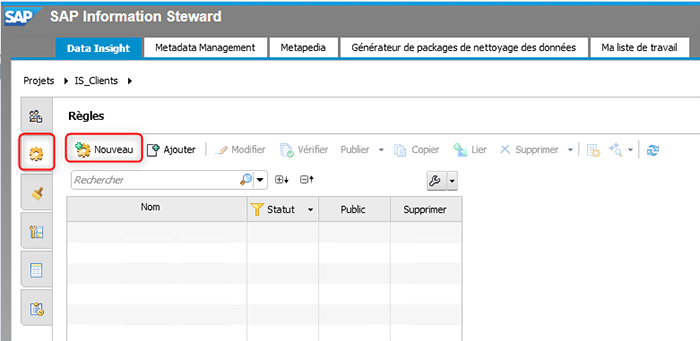
Nous allons dans notre exemple créer deux règles de qualification des données, à savoir :
- VALEUR_NON_NULL, qui va vérifier si les champs de la table IS_CLIENTS sont renseignés
- NUM_TEL_LONGUEUR, qui va vérifier si le numéro de téléphone comporte bien 10 caractères
Nous pouvons voir ci-dessous le détail de la règle « VALEUR_NON_NULL ».
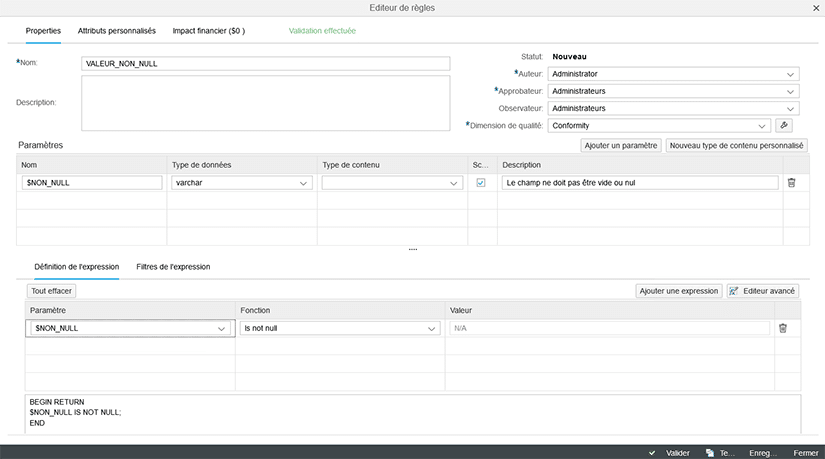
Une fois la règle créée, nous devons la lier aux champs de la table IS_CLIENTS souhaités. Dans notre cas, nous lions cette règle aux champs suivants : âge, pays, région et ville.
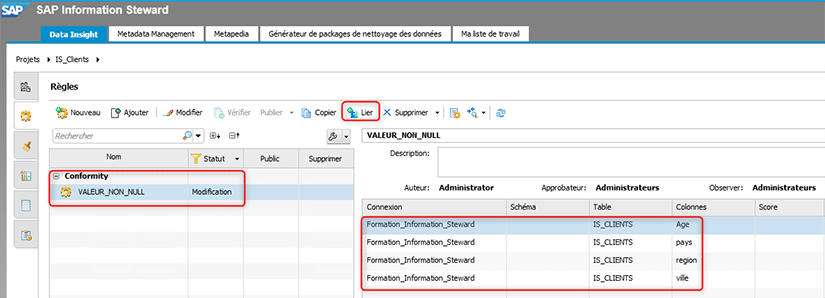
Nous créons dans un second temps notre deuxième règle (NUM_TEL_LONGUEUR), que nous lions au champ « téléphone ».
Configuration du scorecard
Avant de pouvoir calculer le score de fiabilité des données, nous devons configurer les conditions à mettre en place. Pour cela, il faut aller dans l’onglet « Configuration du scorecard » sur le bandeau vertical sur la gauche.
Vous trouverez sur l’image qui suit la configuration mise en place dans notre exemple. On peut notamment voir l’application de nos deux règles créées précédemment.
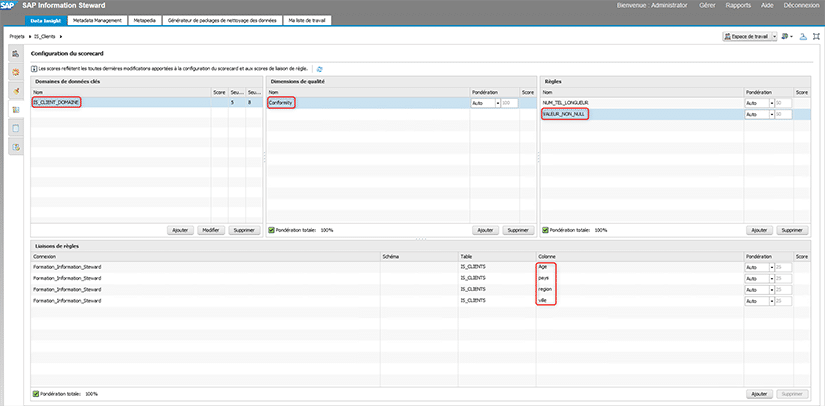
Calcul des scores
Nous allons maintenant calculer les scores de nos données. Pour cela, il faut revenir dans l’onglet « Accueil de l’espace de travail » sur le bandeau vertical sur la gauche puis cliquer sur « Calculer les scores ».
Ci-dessous le résultat obtenu pour notre exemple :
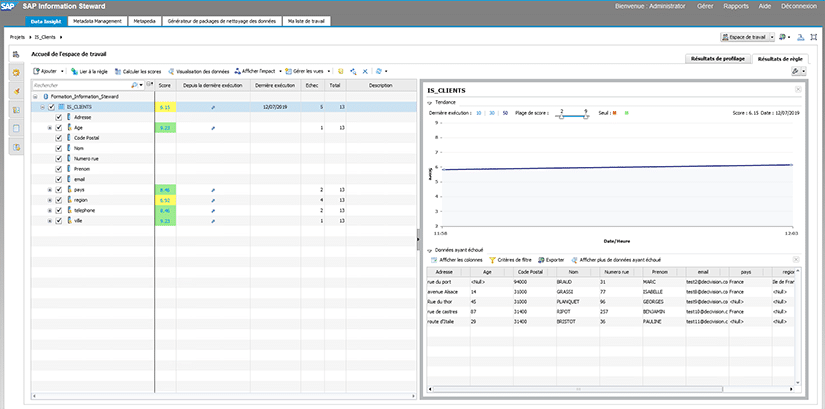
Nous pouvons voir le score (sur 10) obtenu pour chaque champ de la table IS_CLIENTS soumis à des règles de validation, avec le nombre de lignes traitées et le nombre de lignes rejetées.
De plus, nous avons également un score global au niveau de la table IS_CLIENTS. Dans notre cas, ce score est de 6.15 ce qui montre que les données traitées ne sont pas très fiables.
Gestion des métadonnées
Comme décris précédemment, le module « Metadata Management » (ou Gestion des métadonnées) permet de faire du suivi de données présentes sur les différents systèmes. A travers une bibliothèque des métadonnées, il est ainsi possible d’analyser et de comprendre les relations entre les données de l’entreprise.
Ce module a pour objectif de répondre aux difficultés suivantes :
- Faible visibilité des données sur différents systèmes
- Perte de temps dans la collecte des données
- Différents endroits de stockage des données
- Données de différents formats et de différentes représentations
Grâce à ce module, nous allons pouvoir faire correspondre différents environnements systèmes afin de tracer les données de bout en bout. Nous pourrons ainsi voir toutes les transformations subies par celles-ci, et analyser facilement l’impact d’une modification.
Voici un schéma qui résume la communication entre les différents environnements systèmes :
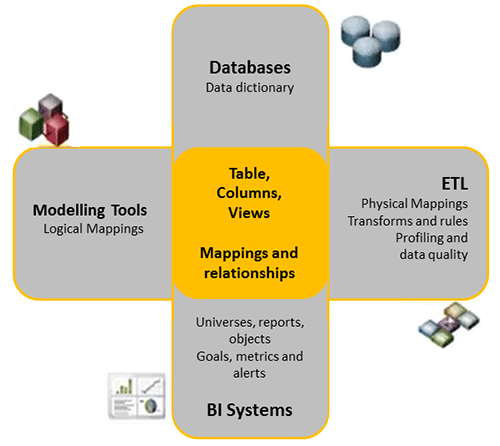
La mise en relation des différents systèmes a de nombreux avantages, à savoir :
- Analyse d’impact de la source de données jusqu’aux tableaux de bords et aux utilisateurs
- Linéage de données d’un tableau de bord jusqu’à sa source de données
- Gestion des métadonnées en provenance de diverses sources, systèmes et/ou technologies
- Réduction des coûts de surveillance en favorisant la réutilisation des données et des tableaux de bord
- Amélioration de la prise de décision
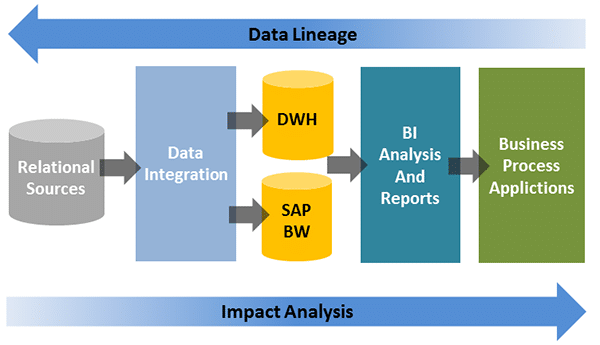
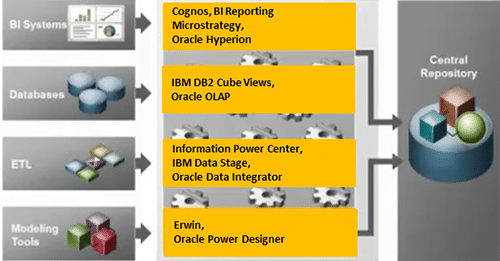
Les différents environnements systèmes considérés ici sont les suivants :
- Base(s) de données relationnelle(s) source(s)
- Base(s) de données du (des) référentiel(s) SAP Data Services
- Base(s) de données de (des) plateformes SAP BI (CMS)
Pour mettre en relation ces différents environnements, il est nécessaire de mettre en place un modèle informatique permettant de décrire l’architecture mise en place dans le système d’information décisionnel de l’entreprise. Ce modèle peut être créé à l’aide de l’outil SAP Power Designer par exemple.
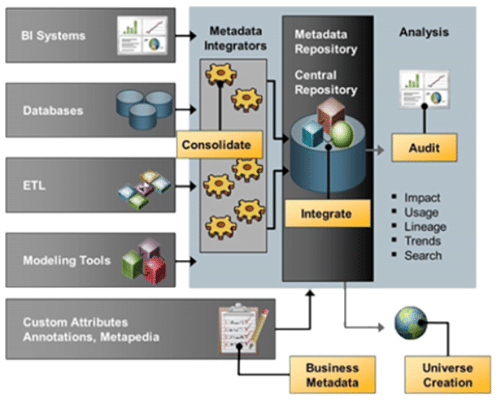
Les métadonnées sont intégrées dans le référentiel central des métadonnées. Nous pouvons ainsi exploiter la mise en relation de ces métadonnées via le référentiel central de métadonnées afin de faire différentes analyses (audit, recherche avancées, impact…).
Voici à présent un exemple de ce que l’on peut faire à travers ce module.
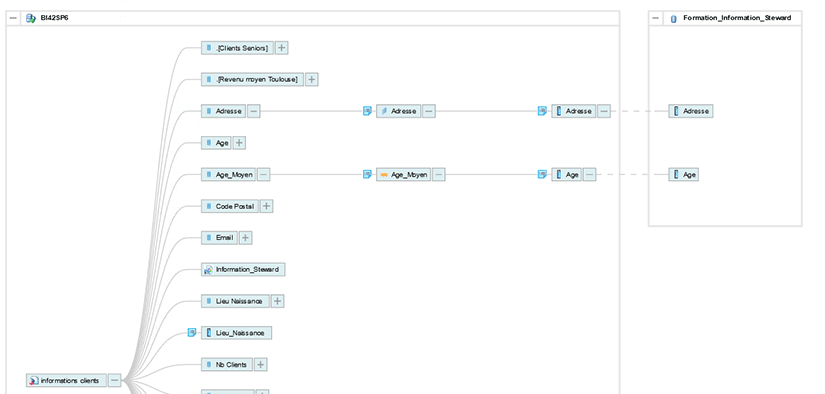
Nous pouvons voir sur l’image ci-dessous les différents environnements systèmes déclarés :
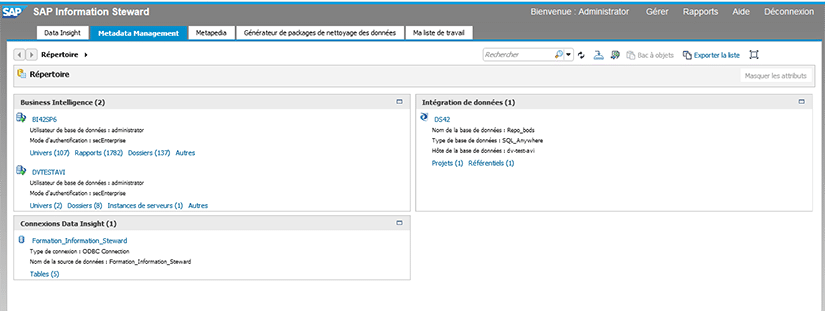
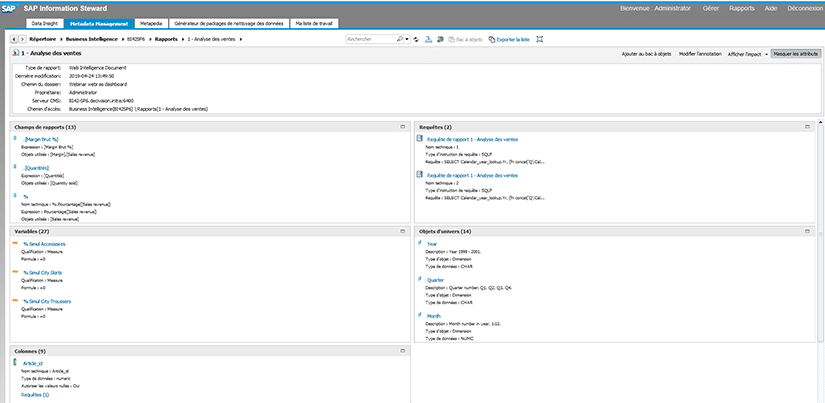
Lorsque nous cliquons sur le système BusinessObjects « BI42SP6 », nous pouvoir observer tout son contenu :
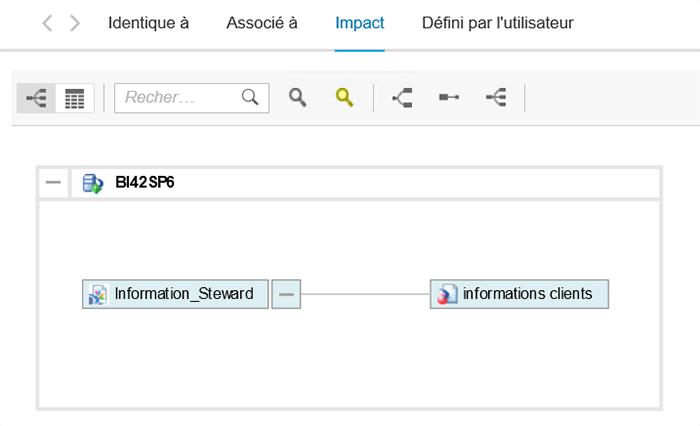
Voici des exemples d’analyse d’impact :
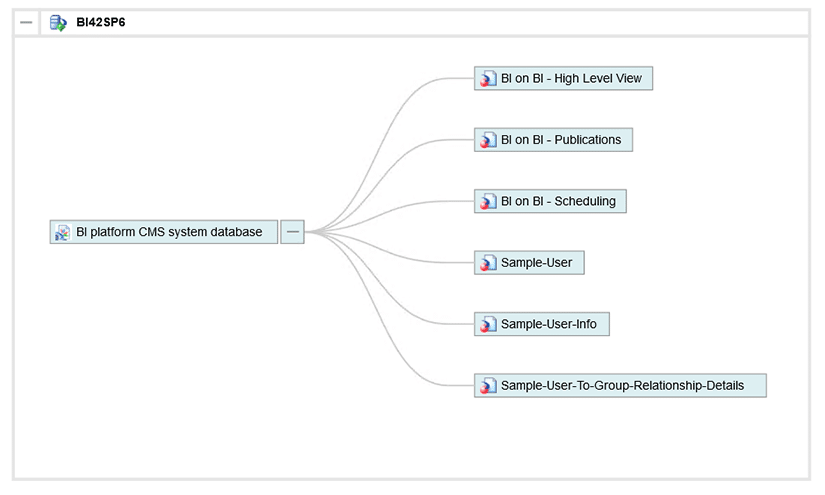
Voici un exemple de linéage de données :
CONCLUSION DE L’EXPERT
L’outil SAP information Steward peut être la solution pour les entreprises qui souhaitent gérer de manière proactive leurs données critiques.
A travers cet article, nous avons pu voir les avantages de cet outil qui permet notamment de mieux comprendre, évaluer, fiabiliser et améliorer les données stratégiques.
Toutefois, cet outil requiert des bases solides dans l’analyse des données, et nécessite un temps d’adaptation afin de pouvoir utiliser tout son potentiel.



