Nécessité de traitement des doublons de données
Les données redondantes sont un problème fréquent dans la plupart des entreprises. Celles-ci entraînent des conséquences préjudiciables. En effet, les doublons peuvent fausser tout type d’analyse, et entrainer de possibles mauvaises prises de décisions.
De plus, les données dupliquées dans plusieurs systèmes auront un cycle de vie différent et peuvent coûter très cher à l’entreprise si elles sont considérables. Elles polluent les processus d’entreprise impactant ainsi la qualité des rapport décisionnels.
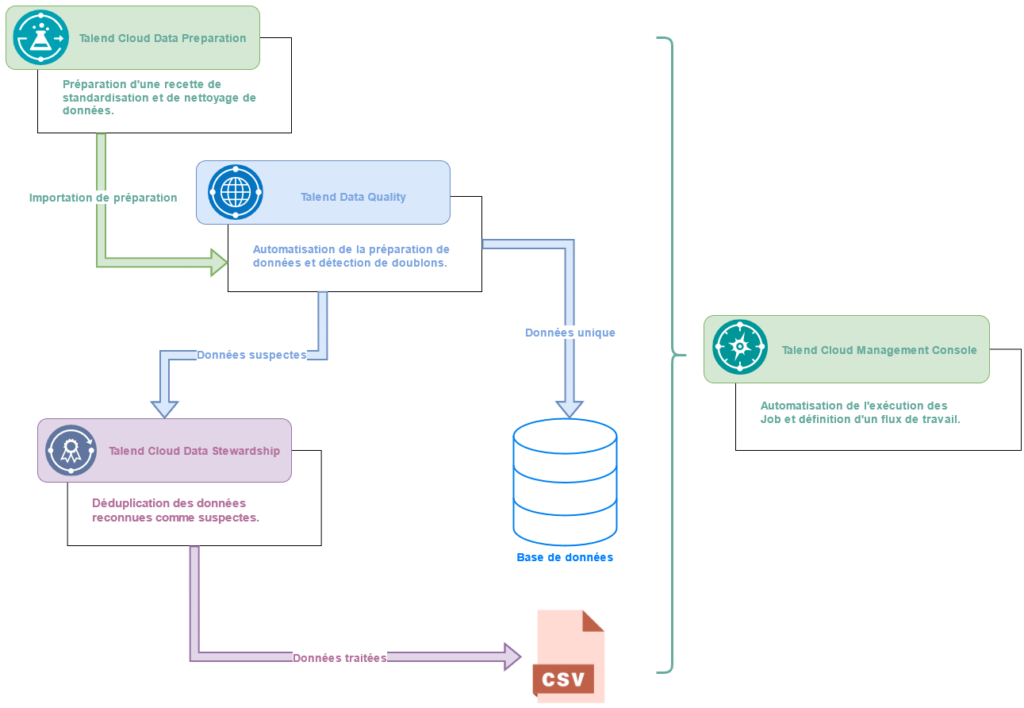
Talend apporte une solution afin de faciliter l’opération de dédoublonnage et déduplication avec des techniques expertes, extrêmement souples et paramétrables. On rappelle que l’opération de dédoublonnage permet la détection de doublons au sein d’une unique base de données, et ce, dans un contexte de gestion de qualité de données. L’opération de déduplication permet la recherche de doublons entre plusieurs fichiers et plusieurs bases de données.
La solution Talend est basée sur des outils Cloud, que sont Talend Cloud Data Preparation, Talend Cloud Data Stewardship et les fonctionnalités Data Quality. Ils permettent d’identifier les doublons, et surtout de les réconcilier. En effet, ces outils permettent d’unifier les informations tout en évitant leur perte. Ils permettent également leur fusion et leur consolidation.
Opération de dédoublonnage
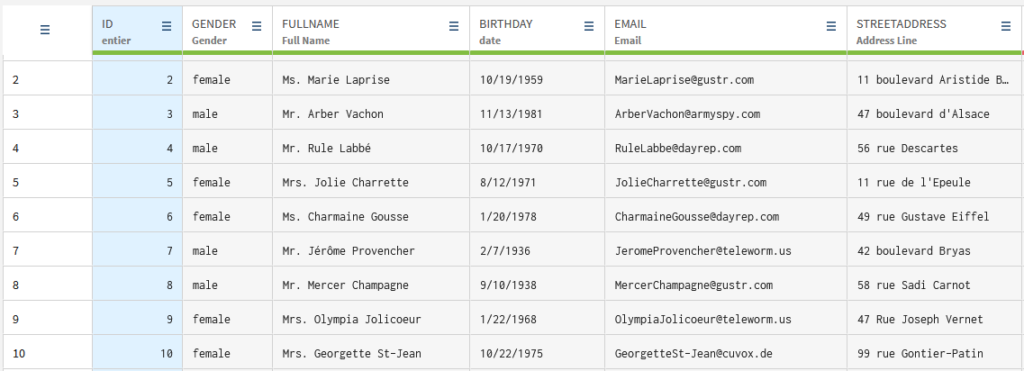
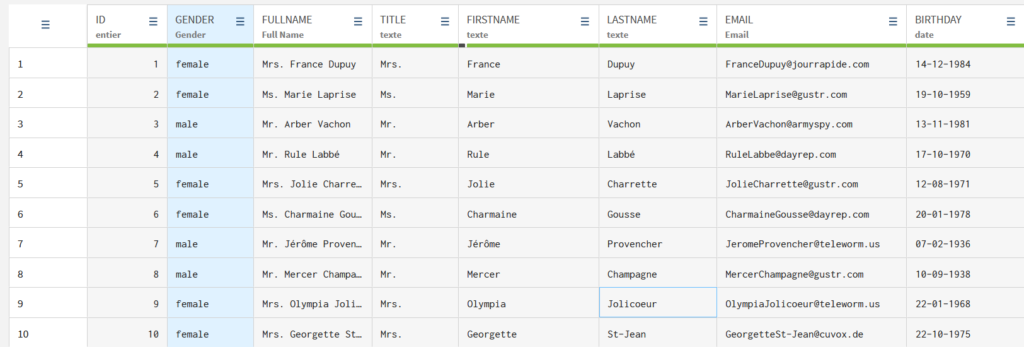
Nettoyage et standardisation des données


Campagne de fusion
Création des tâches de fusion
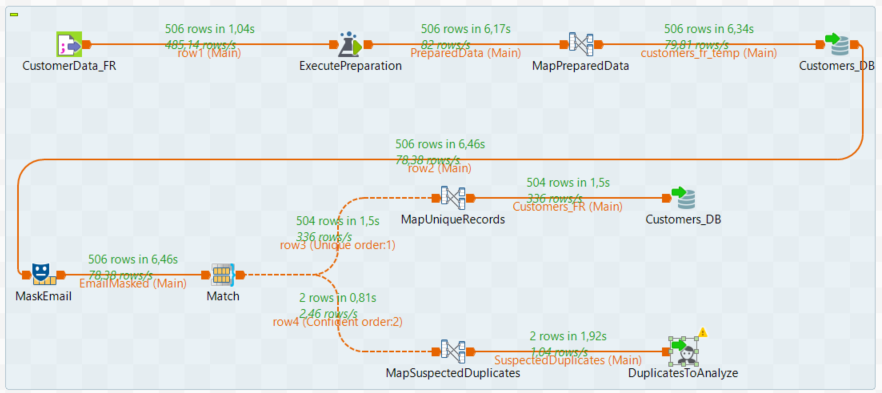
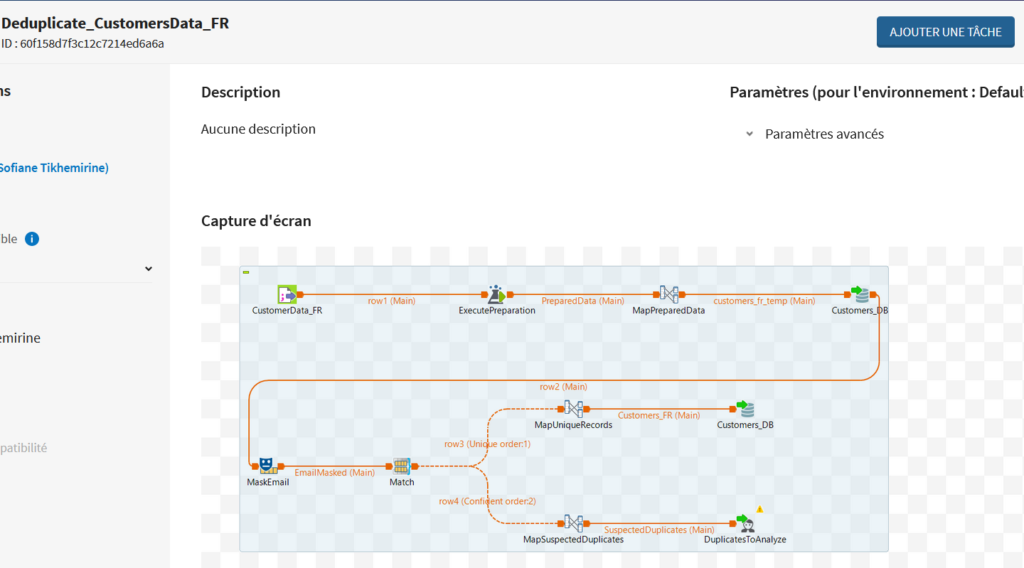
Les tâches de fusion correspondant à une campagne sont créées sur Talend Studio. On ajoute des composants au Job précédent, afin que les données suspectées d’être des doublons soient envoyées sur Talend Cloud Data Stewardship. Les data stewards ajoutés à la campagne de fusion pourront alors traiter manuellement les données.
Toutefois, on souhaite que l’adresse e-mail des utilisateurs soit masquée avant d’être envoyée aux data stewards, on utilise pour cela un composant adapté (tDataMasking). Les données ainsi masquées sont utilisées dans un composant de groupage. On recherche les doublons selon cette règle « nom et prénom quasiment similaire dans la même région » : par exemple, ce composant créera un même groupe pour « Stéphanie Hébert » et « Stéfanie Héberd » si la région est commune (Ile-de-France).
Gestion des tâches de fusion
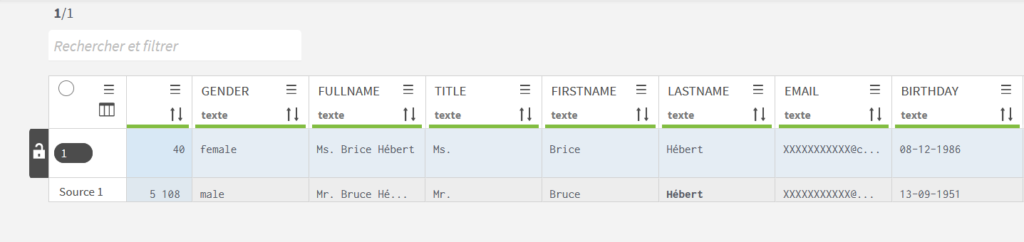
Dans ce cas, le data steward n’a qu’une seule tâche à résoudre. On remarquera que la partie utilisateurs de l’adresse e-mail a bien été masquée.
Les tâches validées peuvent être récupérées à l’aide d’un nouveau Job qui les enregistrera dans la table des clients de la base de données.
Automatisation de l’opération de dédoublonnage
CONCLUSION DE L’EXPERT
Talend propose aujourd’hui des outils puissants permettant d’automatiser des opérations de standardisation et de nettoyage de données. Ces outils peuvent être utilisés ensemble afin de répondre à des besoins spécifiques. Par exemple, vous pouvez adapter la recherche de doublons à votre avantage en la configurant pour détecter les personnes habitant dans un même foyer.
Le principal atout que l’on peut retirer de ces outils est l’aspect collaboratif. En effet, grâce à Talend Cloud Data Preparation et Talend Cloud Data Stewardship, la gouvernance de données et la gestion de données de qualité est l’affaire de tous.
Nous sommes désormais partenaire Gold Talend afin de vous assurer le meilleur niveau d’expertise sur les différents outils de la plateforme.



