Introduction
A une époque ou l’on parle beaucoup d’outils de développement « Low Code/No Code » notamment dans le domaine de la Business Intelligence autour de la Data Intégration, cela fait quelques années qu’un outil est en train de bouleverser les codes. Il s’agit de Data Build Tool (DBT).
Qu'est-ce que Data Build Tool (DBT) ?
Présentation générale
DBT ou Data Build Tool est un outil de transformation de données. Plus précisément il s’agit d’un projet Python open-source qui a été publié pour la première fois en décembre 2021. Il est important de noter que DBT ne fait techniquement pas partie de la famille des ETL (Extract, Transform, Load) car il n’est conçu que pour la partie transformation de la donnée et ne permet pas d’extraire des données depuis des fichiers ni de charger dans autre chose que l’entrepôt de données auquel il aura été associé.
DBT se décline en deux versions.
– DBT Core, la version gratuite qui possède l’intégralité des fonctionnalités DBT mais sans interface graphique. Cet outil est basé sur des lignes de commandes pour exécuter des scripts SQL, des macros, des tests et des fichiers de configurations. Il s’agit d’une solution adaptée pour les projets data complexes et où l’optimisation du temps de traitement et de l’espace de stockage ont une place importante.
– DBT Cloud, la version payante proposant de nombreux outils visuels supplémentaires. Cette version est également recommandée si la base de données est une solution cloud.
Dans cet article, nous allons nous concentrer sur la version DBT Core.
Architecture de DBT
Les éléments principaux de DBT Core dans l’ordre d’intervention et leurs fonctions respectives sont les suivants :
- Source de données : Votre entrepôt de données contenant les données brutes.
- Modèles DBT : Vos fichiers SQL définissant les transformations.
- Compilateur DBT : Le cœur de DBT qui interprète vos modèles et génère le SQL final.
- Tests DBT : Les tests que vous définissez pour vérifier la qualité des données.
- Documentation DBT : La documentation générée automatiquement.
Vues et tables transformées : Les données prêtes à être utilisées pour vos rapports et analyses.
Les prérequis
Python
DBT Core est un package Python récent, il nécessite une version Python 3.8 ou supérieure pour pouvoir fonctionner. Il peut être installé via les outils apt-get, yum, pip, ou bien alors en clonant directement le repository git dbt. La plupart des OS sont capables de l’héberger, à savoir : CentOS, MacOS, Ubuntu, Debian et Windows. Selon l’OS, des dépendances supplémentaires peuvent être nécessaires.
Connexion à une base de données
DBT Core se base sur l’exécution de scripts SQL et doit par conséquent être connecté à une base de données. Par défaut, DBT peut se connecter aux bases de données suivantes :
- AlloyDB
- Apache Spark
- Athena
- Azure Synapse
- BigQuery
- Databricks
- Dremio
- Glue
- Materialize
- Microsoft Fabric
- Oracle
- Postgres
- Redshift
- Snowflakes
- Teradata
Toutefois, puisqu’il s’agit d’un projet open-source, de nombreuses plateformes de données ont développé leur propre adaptateur dédié à DBT. C’est le cas par exemple de Hive, MySQL, SQL Server, Impala, SQLite pour ne citer qu’elles. Et il est toujours possible de connecter nativement une base de données à DBT si son adaptateur n’existe pas encore.
Extraction
Puisque DBT n’est pas conçu pour se charger de l’extraction, il est donc nécessaire d’avoir un outil d’extraction de donnée et de chargement données dans la base de données sur laquelle est connectée DBT. Cela peut être un outil d’Ingestion de données (Stitch, Airbyte, Qlik Talend Cloud, Apache Kafka etc etc) ou directement avec du Script (Python par exemple).
Inscrivez-vous à la newsletter DeciVision !
Soyez notifiés de nos derniers articles de blog, de nos prochains webinars et nos actualités !
Versionning
Travailler avec DBT c’est coder en SQL, changer des fichiers de configuration, structurer ses dossiers et parfois se plonger dans du Python et des scripts Shell (ou batch/powershell pour Windows). Il est donc primordial d’utiliser un outil de versionning tel que Git pour gérer tout cet environnement de fichiers. Les connaissances de base de Git suffisent à cet usage.
Le paradigme DBT
Les modèles SQL
La principale force de DBT est de pouvoir développer les opérations de transformation de données à très bas niveau. C’est-à-dire en codant directement les requêtes SQL voulues. Ces scripts SQL – appelés « modèles » – s’accompagnent de plusieurs outils pour les rendre dynamiques et personnalisables.
Exemple de modèle SQL DBT :
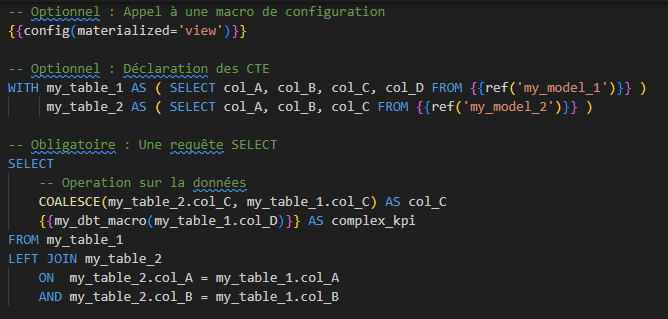
Jinja & Macros
Si vous êtes habitués au SQL, la première chose choquante dans l’exemple précédent est l’usage du motif `{{ nom_fonction() }}`. Il s’agit d’une méthode d’encapsulation appelé « Jinja ». Elle permet d’inclure du Python dans du SQL. Cela permet une approche modulaire de la transformation de la donnée. Cela favorise la factorisation du code, améliore la maintenabilité des projets et permet de créer des pipelines complexes, structurées par différents modèles.
Les fonctions ainsi appelées via Jinja sont appelées « macros ». Lors de la compilation, une macro sera exécutée et renverra un bout de SQL pour compléter la requête.
Exemple une foi compilé :
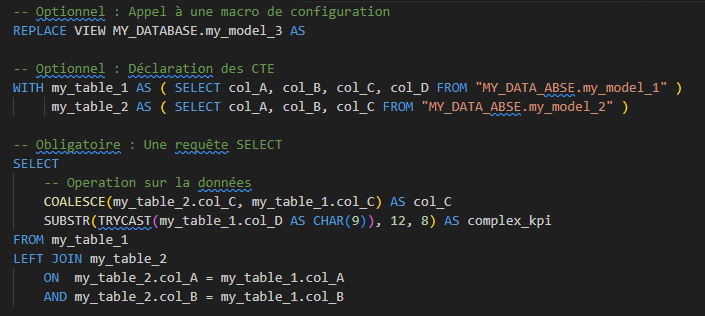
Tests intégrés
La qualité de données est un critère primordial. DBT dispose de fonctionnalités de tests directement intégrées au sein du projet. Ces tests peuvent être exécuté au sein du pipeline afin d’assurer la qualité des données qui y circulent. Comme pour les macros Jinja, il existe des test prédéfinis mais il est possible de créer ses propres tests pour vérifier la donnée.
L'arborescence fichier
Un projet DBT se constitue donc d’un ensemble de fichiers. Les bonnes pratiques de DBT suggèrent l’arborescence suivante à la racine du projet :
- `models`. Ce dossier contiendra tous les scripts `sql` pour la transformation de données.
- `test`. Dans ce dossier se trouveront différents fichiers `yml` dédiés aux tests unitaires, d’intégration voire fonctionnels.
- `seeds`. Ce dossier englobe les scripts `sql` consacrés à la récupération de source de données comme, par exemple des référentiels, des tables techniques, des paramètres, des métadonnées, etc. On pourrait voir ça comme une partie « extraction » de données, mais il faut garder en tête que DBT ne peut récupérer de la donnée que d’une base de donnée.
- `macros`. C’est ici que se trouveront les macros, élément essentiel à DBT.
- `snapshot`. Il est possible avec DBT de mettre en place un système de snapshots, c’est-à-dire une sauvegarde de l’état de la base de données à un instant précis. Cela peut être utile pour certains tests ou la mise en place de backups. C’est dans ce dossier que cette fonctionnalité sera configurée.
- `assets`. DBT propose un outil de génération de documentation, c’est ici que seront sauvegardés les fichiers générés pour cette documentation.
Cette arborescence est une suggestion de DBT et peut être altérée au besoin. DBT reste très permissif là-dessus mais ne permet l’existence de doublons dans le nom des fichiers. D’autres dossiers seront générés automatiquement par DBT et doivent être conservés tels quels.
- `logs` contiendra les fichiers de logs des exécutions, compilation ou toute autre commande dbt exécutée dans un terminal. La génération de ses logs peut être configurée au besoin pour ne pas prendre trop d’espace dans l’environnement.
- `target`. Les scripts présents dans le dossier `models` doivent être compilés avant exécution. Le dossier target contiendra le résultat de cette compilation.
Configuration & Documentation
Toute l’organisation d’un projet DBT se base sur des fichiers de configuration `yml`. Chaque fichier `yml` permet de configurer les modèles et les sous-dossiers où ils se situent. Chaque dossier peut contenir un ou plusieurs `yml`. Un fichier `yml` peut prendre n’importe quel nom, du moment qu’il n’y a pas de doublons. Si un dossier n’a pas de fichier `yml` attitré, il héritera de la configuration du dossier parent. La factorisation, le nommage et l’arborescence de toutes ces configurations sont à gérer selon les besoins du projet. Toutefois, bien que DBT reste très permissif sur ce point, il y a quelques exceptions qui s’appliquent.
Les fichiers `yml`suivants sont requis à la racine du projet par DBT pour son bon fonctionnement.
- `dbt_project.yml`, contient toutes les configurations par défaut de votre projet. Si vous voulez par exemple avoir tous les modèles de votre projet par défaut en matérialisation « materialized_view », vous pouvez le déclarer ici et changer la configuration uniquement dans les sous dossiers ou scripts concernés.
- `packages.yml`, liste les différents package communautaires dont votre projet a besoin. Il peut s’agir d’un adaptateur à une base de données qui n’est pas présente par défaut, une librairie de macro précise pour votre projet, un outil graphique pour votre IDE, etc.
- `profiles.yml`, contient toutes les informations liées au profil de l’utilisateur, les variables d’environnement pour la base de données, les restrictions ou sécurité nécessaire pour l’environnement actuel
Les fichiers `yml` permettent également la génération d’une documentation quasi automatique de la part DBT, pour peu que ces fichiers soient maintenus à jour.
AVIS DE L’EXPERT
Avantages
- Collaboration simple : Sous couvert de l’usage d’un outil de versionning, DBT est un outil très facile à manipule au sein d’une grosse équipe avec beaucoup de contributeurs.
- Agilité : La modularité de DBT permet de s’adapter rapidement à de nouveaux besoins
- Assurance de qualité : Grâce aux test intégrés de DBT, les erreurs sont vite identifiables et le débogage facilité
- Personnalisation accrue : Les nombreux outils de configurations et le développement bas niveau de modèles SQL, couplés à la force de Jinja, permettent de répondre à n’importe quel besoin – aussi précis soit-il – de transformation de données tout en restant le plus optimal possible.
- Connectivité : DBT peut se rattacher à la grande majorité des entrepôts de données populaires du marché de la BI.
Inconvénients
- Absence d’interface graphique : Travailler avec DBT Core c’est travailler dans un IDE comme pour développer un projet d’architecture logiciel. Ce n’est pas la méthode de travail la plus populaire au sein de l’écosystème de la BI
- Prérequis nombreux : DBT nécessite d’avoir un minimum de connaissance dans plusieurs autres outils, SQL, Python, Shell, Git. La courbe d’apprentissage initiale peut rebuter certains
- « Transform only » : DBT a été conçu uniquement pour la partie Transformation de la donnée. Par conséquent il n’est pas facile de changer de solution ETL pour DBT car il faudra d’autre outils pour gérer l’extraction et le chargement.
- Dépendance à un entrepôt de données. DBT, contrairement à d’autres ETL, se doit d’être constamment connecté à une base de données externe.
- Workflow Natif peu pratiquegrâce aux macros `ref` et `source` il est possible de créer un workflow DBT uniquement via des dépendances entre modèle, et de configurer la commande `dbt run` pour exécuter ce workflow. Toutefois, il est conseillé de passer un ordonnanceur externe ou un outil de CI/CD pour un workflow plus complet et manipulable.



