Introduction
Lorsqu’on travaille avec des volumes de données importants, l’ingestion de fichiers devient rapidement un enjeu clé. Dans un contexte où les sources de données sont multiples et évolutives, il est essentiel de mettre en place des processus automatisés, capables de traiter plusieurs fichiers en parallèle sans intervention manuelle.
Azure Data Factory est une solution puissante pour orchestrer ces flux de données. Mais comment optimiser l’ingestion de plusieurs fichiers simultanément sans complexifier inutilement les pipelines ? Dans cet article, nous allons voir comment paramétrer efficacement Azure Data Factory pour traiter plusieurs fichiers en parallèle.
Azure Data Factory
Azure Data Factory est une plateforme d’intégration de données dans le cloud, proposée par Microsoft. Elle permet de concevoir, d’orchestrer et de superviser des pipelines d’intégration de données, transformant ainsi des données brutes en informations exploitables. Grâce à son architecture basée sur le cloud, Azure Data Factory est capable de gérer des volumes massifs de données provenant de différentes sources et de les acheminer vers des destinations variées pour analyse, stockage ou reporting.
Présentation de l’ingestion dans Azure Data Factory
L’ingestion de fichiers est l’une des fonctionnalités clés de Azure Data Factory, permettant d’extraire, de transformer et de charger des fichiers vers des destinations variées, comme un Data Lake, une base de données ou un entrepôt de données cloud.
L’ingestion de fichiers dans Azure Data Factory peut se faire de plusieurs manières :
- Copie simple : transfert direct des fichiers d’une source à une destination.
- Traitement en masse : ingestion de plusieurs fichiers à la fois grâce à des paramètres dynamiques et des boucles.
Comme mentionné dans l’introduction, l’objectif de cet article est de montrer comment réaliser l’ingestion de masse. Nous allons voir comment mettre en place cette approche efficace en utilisant des paramètres et des fichiers JSON pour automatiser et structurer le chargement des données.
Paramétrer les data sets
Dans Azure Data Factory, un data set représente la structure des données que l’on souhaite traiter. Il agit comme une liaison entre la source et les activités qui manipulent les données.
Remarque : Un data set ne contient pas de données, mais il définit où elles se trouvent et comment elles sont structurées.
L’un des éléments clés pour gérer plusieurs fichiers simultanément dans Azure Data Factory est l’utilisation de paramètres dynamiques dans les data sets. Dans notre exemple, nous allons effectuer l’ingestion de masse de plusieurs fichiers Excel provenant d’un compte de stockage Blob vers un compte de stockage Data Lake Gen 2.
1. Paramétrisation des datasets
Pour rendre un dataset dynamique, on peut ajouter des paramètres qui définissent le chemin du fichier, son nom, ou son extension.
Ces paramètres permettent d’éviter de créer un dataset statique pour chaque fichier et facilitent l’automatisation du processus d’ingestion.
2. Injection des paramètres dans le pipeline ForEach
Les paramètres définis au niveau du dataset sont ensuite remplis dynamiquement dans l’activité de copie, où une boucle ForEach est utilisée pour parcourir la liste des fichiers à traiter.
Pilotage de l’ingestion de masse
Une source de données comme un fichier JSON ou une table de contrôle dans une base SQL peut être utilisée pour piloter l’ingestion.
Dans le cas d’un fichier JSON, celui-ci doit contenir la liste des fichiers à ingérer et suivre une structure bien définie :

Grâce à l’activité Lookup, Azure Data Factory peut lire le fichier JSON, extraire la liste des fichiers et les traiter un par un dans la boucle ForEach.
Inscrivez-vous à la newsletter DeciVision !
Soyez notifiés de nos derniers articles de blog, de nos prochains webinars et nos actualités !
Cas pratique
Contexte : L’objectif est d’ingérer automatiquement les fichiers d’un conteneur Blob Storage vers un conteneur Data Lake à l’aide d’Azure Data Factory.
Etape 1 : La première étape consiste à définir les paramètres nécessaires et à les assigner aux datasets source et destination afin de permettre une ingestion dynamique des fichiers.
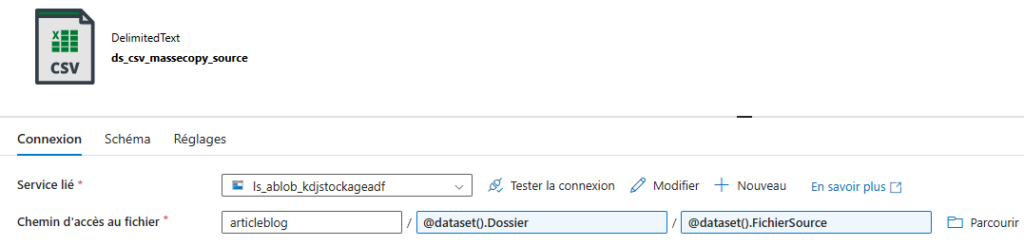
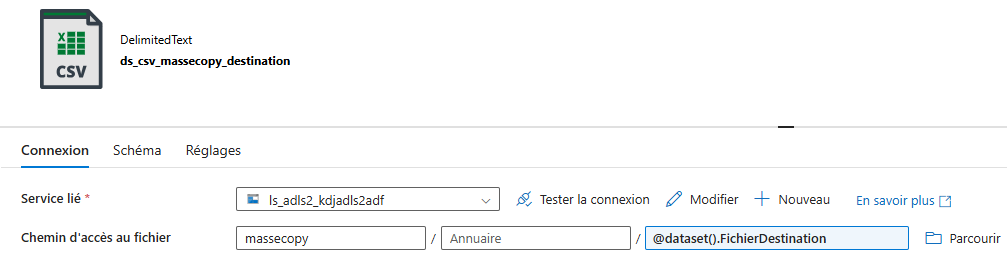
Etape 2 : Une fois ces paramètres configurés, il faut construire un fichier JSON de pilotage d’ingestion et créer un dataset associé à ce fichier, qui servira de référence pour le pipeline.


Etape 3 : Dans la troisième étape, on construit le pipeline Azure Data Factory et on y ajoute une activité LookUp pour interroger le fichier JSON et récupérer la liste des fichiers à traiter.
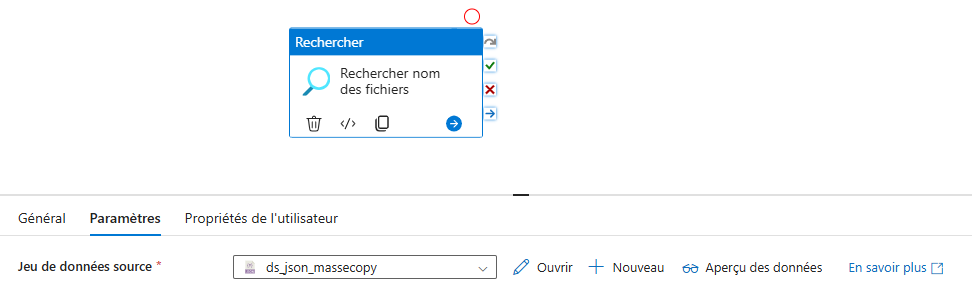
Etape 4 : Ensuite, on intègre une activité ForEach, dont la sortie est alimentée par les résultats de l’activité LookUp.
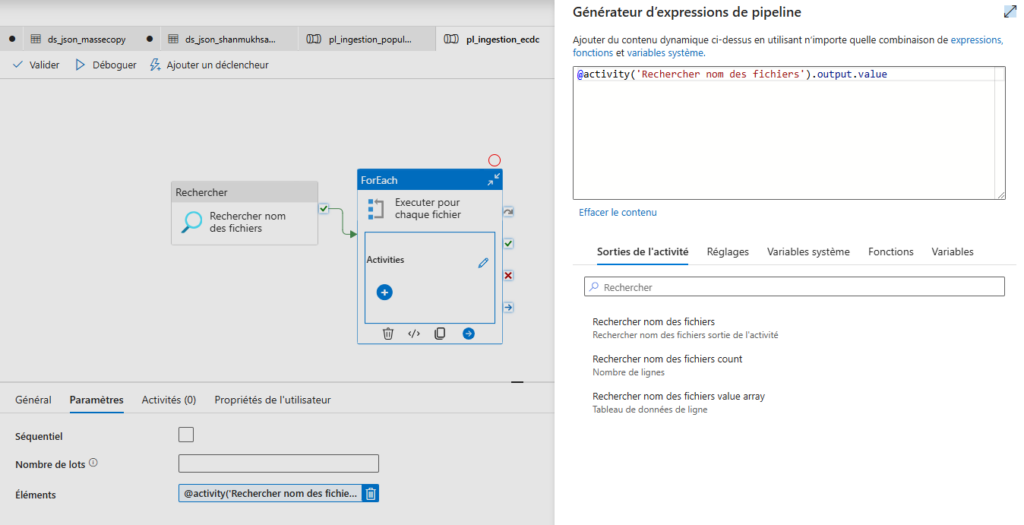
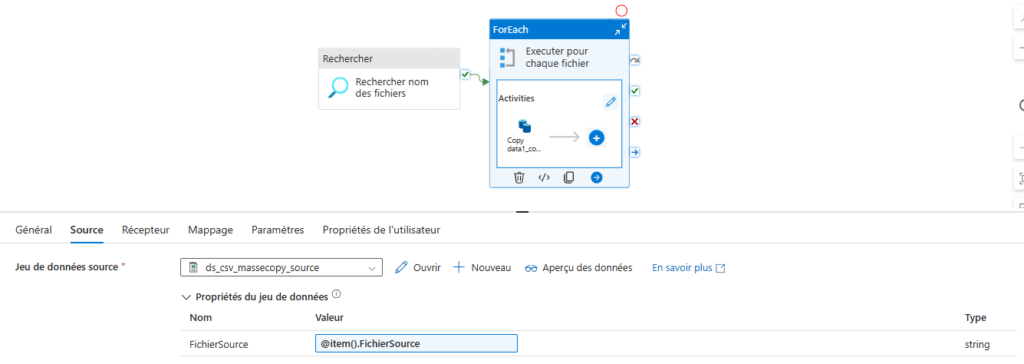
Etape 5 : À l’intérieur de la boucle ForEach, on insère une activité de copie, qui prend en compte les entrées du fichier JSON pour définir dynamiquement les valeurs des variables.

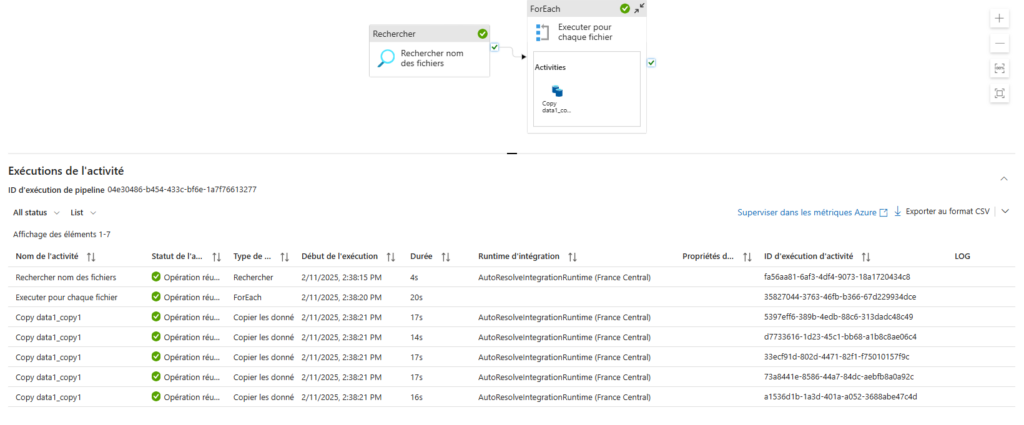
Etape 6 : Enfin, la dernière étape consiste à exécuter le pipeline et à vérifier que les fichiers ont bien été ingérés dans le Data Lake conformément aux attentes.

CONCLUSION DE L’EXPERT
L’ingestion de plusieurs fichiers simultanément dans Azure Data Factory peut être grandement facilitée par l’utilisation de paramètres dynamiques et d’un fichier JSON pour centraliser la gestion des fichiers. Cette approche permet de rendre les pipelines plus modulaires, évolutifs et faciles à maintenir.
En optimisant le traitement en parallèle, il est possible d’améliorer la rapidité des flux ETL et d’assurer une intégration fluide des données dans l’écosystème Azure.
Pour aller plus loin, il est recommandé d’intégrer une gestion des erreurs et des logs afin de suivre l’état des fichiers traités et de garantir une ingestion robuste et fiable.



