Introduction
Fonctionnalité introduite avec SAP HANA 1.0 SPS 06, le SAP HANA Smart Data Access répond à des besoins importants en termes d’accès à des sources de données externes, indépendamment de leur emplacement et/ou du SGBD hôte.
L’accès « intelligent » vous permet d’accéder aux données distantes comme si ces données étaient stockées dans les tables locales du repository SAP HANA, mais, sans les copier dans le système, en créant seulement des tables virtuelles.
Depuis le lancement de cette innovation majeure, SAP a beaucoup amélioré cet outil, qu’il faut cependant veiller à ne pas confondre avec les composants Smart Data Integration (SDI) et Smart Data Quality (SDQ).
Note : SDA est inclus dans la plateforme SAP HANA Il n’est pas déployé de base, il est nécessaire de télécharger des packages d’installation supplémentaires via le lifecycle management de la base de données SAP HANA (HDBLCM).
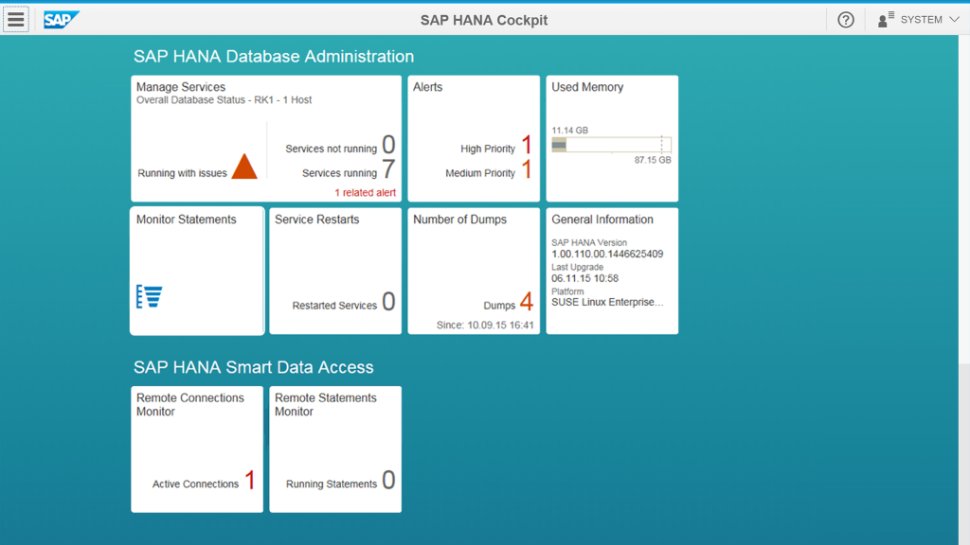
Le SDA depuis le HANA cockpit
Prérequis de déploiement
- Un système SAP HANA de version 1.0 SPS 06 minimum ;
- Les drivers nécessaires correspondants aux SGBD des bases de données distantes, doivent être installés sur chacun de vos nœuds HANA (cf. https://launchpad.support.sap.com/#/notes/1868702).
- Disposer d’une base de données distante accessible depuis votre serveur HANA, hébergée sur un des SGBD suivants (HANA 02 +) ou sur un autre SGBD étant listé dans la documentation des prérequis SAP : SAP (HANA, BEx Queries, Sybase), Netezza, Oracle, Teradata, MS SQL Server, Hive, Hadoop, IBM DB2.
- Les rôles requis ci-dessous :
- Pour gérer les sources de données distantes :les system privileges CREATE REMOTE SOURCE et CREDENTIAL ADMIN ;
- Pour créer et gérer les tables virtuelles :à minima l’object privilege CREATE VIRTUAL TABLE ainsi que, selon vos besoins, les droits supplémentaires pour les instructions SQL (INSERT, UPDATE, …) ;
Configurer le SDA sur votre plateforme HANA
La première étape que nous aborderons ici est la création d’une source de données distante via l’outil SAP HANA Studio. Dans notre exemple, nous accéderons à une seconde base de données HANA à distance, via le connecteur ODBC préalablement configuré.
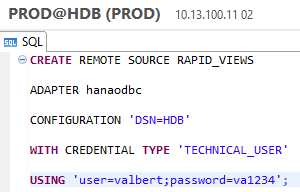
Vous pouvez créer une source de données distante via la console SQL, directement dans l’outil SAP HANA Studio :
Ou directement via l’interface utilisateur prévue à cet effet :
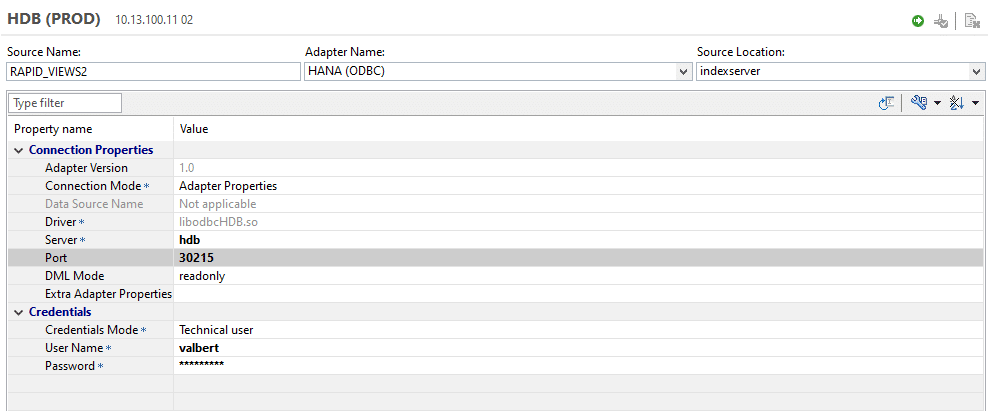
Dans l’explorateur d’objet de SAP HANA Studio, on peut visualiser les données distantes de la même manière que des catalogues locaux.
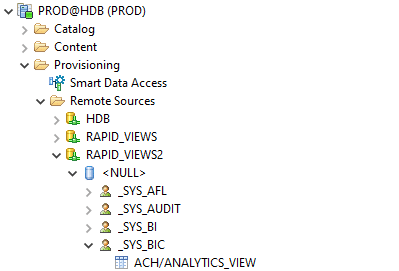
Une fois votre source de données créée, toutes les tables à disposition sont affichées comme ressources. Attention, en tant que telles, elles ne sont pas exploitables, mais simplement visibles et disponibles à la consultation.
Il est donc nécessaire de réaliser le mappage de votre table virtuelle avec les données de votre base distante. Cette opération est réalisable par script SQL ou via le menu contextuel comme ci-dessous :
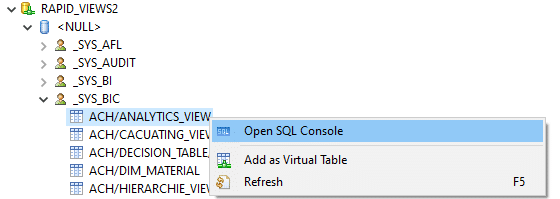
Cette table étant mise à disposition dans votre catalogue en tant que table virtuelle, avec toutes vos autres tables, vous pouvez l’utiliser comme source de données pour vos modélisations.
Ci-dessous un exemple de création d’une Calculation View :
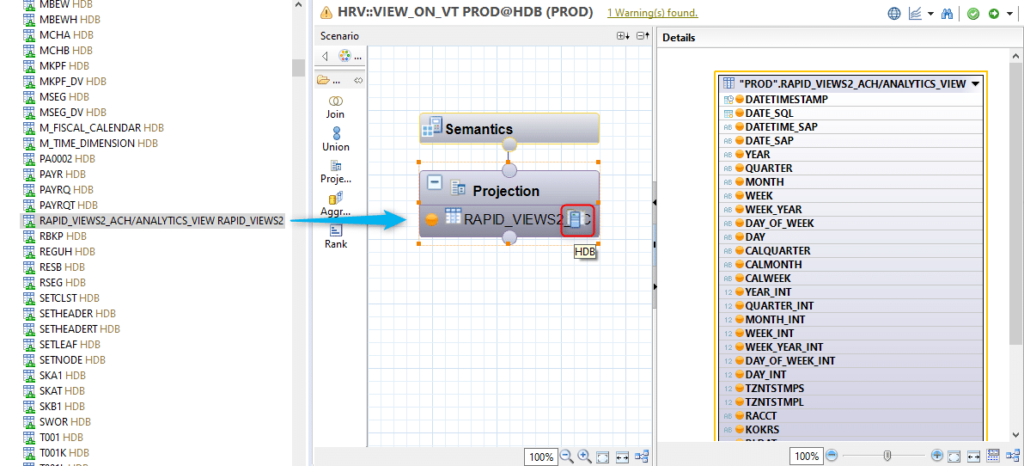
Note : l’icône  apparaît à côté du nom des tables issues des sources de données distantes.
apparaît à côté du nom des tables issues des sources de données distantes.
Exemple de combinaison de données : l’interaction BW4HANA / HANA via le SDA
Il est possible avec le même adaptateur ODBC que précédemment, d’établir une connexion distante avec un système BW4HANA. Via la même méthode, on peut alors récupérer et utiliser en tant que source une table BW.
Il est important de noter qu’on peut aisément mixer les sources de données dans une même vue de calcul par exemple. Tel que représenté ci-dessous avec des sources HANA & BW4HANA :
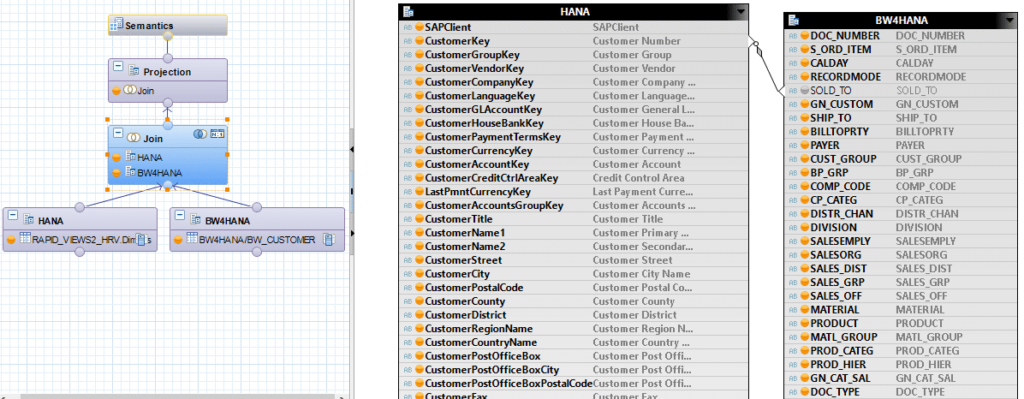
Après avoir trouvé les jointures nécessaires, on retrouve en sortie, un résultat propre contenant des données consistantes et homogènes provenant des 2 systèmes sources. Dans notre exemple nous avons jointé les données historiques d’un client provenant de notre système BW avec les données actuelles de ce même client provenant de notre système HANA.
Notre avis : C’est un moyen intéressant de construire des combinaisons de données rapidement et assez facilement. L’interprétation des types de données étant automatique, il n’est pas nécessaire de transformer les données afin d’homogénéiser le résultat.
CONCLUSION DE L’EXPERT
Une fois les interpréteurs configurés côté serveur, la mise en place de ces connexions à distances permet aux utilisateurs d’accéder très facilement à des données hétérogènes distantes. Toutes ces données sont accessibles depuis le même outil SAP HANA Studio. Cette méthode a l’avantage de ne pas affecter les utilisateurs finaux, pour eux, les tables et les données semblent provenir du même emplacement.
Ainsi, pour des entreprises possédant des architectures de SI complexes et hétérogènes en termes de sources de données, cet outil vient faciliter le transit de données vers le système HANA, qui de son côté permet d’optimiser les performances. Cet outil permet aussi d’unifier l’accès aux données ainsi que les moyens de reporting dans l’entreprise.
Le SDA est particulièrement efficace pour traiter les données issues de systèmes Hadoop et pour la migration de base de données backend sans impacter l’utilisateur final. Il est en revanche moins efficace pour les traitements rapides de données, les traitements en temps réel, pour les besoins de data cleaning ou de transformation de données. Il se différencie en ce sens d’un ETL.
Il permet notamment de faire des migrations et consolidations de données sans impacter vos utilisateurs finaux qui n’interrogeront que la source HANA. Cet outil est particulièrement conseillé dans le domaine du big data, là où les entrepôts de données physiques sont souvent difficilement accessibles par les utilisateurs finaux.



