Le stockage des données pose aujourd’hui de nombreux problèmes aussi bien d’infrastructures, de scalabilité ou de coût. Des solutions de Data cloud pour résoudre ces problèmes ont vu le jour durant le 21-ème siècle et c’est notamment le cas du précurseur du marché : Snowflake.
Qu’est-ce que Snowflake ?
Snowflake est un éditeur d’une solution d’infrastructure de données dans le cloud créée en 2012 en Californie, permettant de centraliser les données provenant de multiples sources afin de s’en servir pour de l’analyse, de la BI ou par exemple des modèles de machine Learning. Apparu en tout premier sur le marché du Data Cloud avant AWS, GCP et Azure, Il a été mis sur le marché en octobre 2014.
Snowflake est un SaaS qui se distingue par son architecture innovante qui rend possible le stockage et l’analyse de données à grande échelle. Il a pour mission de résoudre les problèmes imposés par le Big Data.
Chaine Décisionnelle avec Snowflake
Il existe de nombreux moyens et méthodes d’intégrer Snowflake dans une chaine de décisionnelle aussi bien en tant qu’ODS, DataWarehouse ou même Data Lake.
On peut donc facilement imaginer un fonctionnement de Snowflake en tant que Data Warehouse, possédant en entrées des sources de données applicatives de tout type qui serait transformées à l’aide de flux ETL.
Afin d’illustrer cette opération, nous allons dérouler un petit cas d’étude de la mise en place d’un Data Warehouse avec Snowflake, tout en utilisant dans notre exemple Talend pour l’intégration des données et Power BI pour le reporting. On obtient donc la chaine décisionnelle suivante :
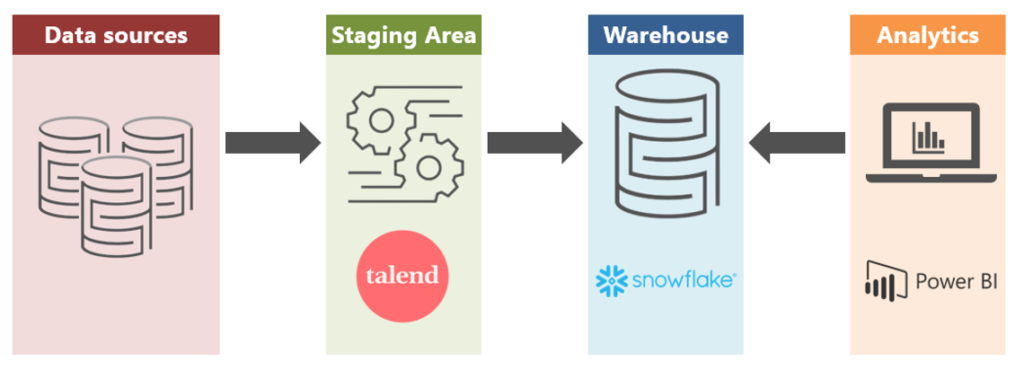
Préparation de la plateforme Snowflake
Dans une première phase, nous devons préparer notre plateforme Snowflake à la réception des données. On crée une base de données qui permettra de stocker nos données dans un schéma de tables :

Elle est composée de deux schémas de données, le premier « Infomation_Schema » qui contient toutes les méta données de cette base, et le deuxième notre schéma « public » que nous allons utiliser pour l’importation des schémas de nos tables de données :

On met ensuite en place deux Virtual Warehouse qui permettent d’exécuter des requêtes SQL et charger des données par exemple. Chaque Virtual Warehouse a « une force de calcul » dédiée, cela signifie que les performances de l’un ne vont pas influer sur un autre. Il est aussi important de bien définir la taille d’un Virtual Warehouse afin d’avoir une gestion des coûts correcte et la bonne échelle par rapport aux besoins. L’un des Virtual Warehouse permettra de réaliser l’importation des données transformées depuis Talend et le deuxième de réaliser les requêtes de reporting depuis par exemple Power BI. On peut donc vérifier la liste de nos Virtual Warehouse et leurs statuts actuel sur Snowflake :
On pourrait aussi mettre en place une dernière étape de préparation en créant des ressources monitors permettant de limiter la quantité de crédit dépensée par les Virtual Warehouse dans un intervalle de temps défini ou non.

Inscrivez-vous à la newsletter DeciVision !
Soyez notifiés de nos derniers articles de blog, de nos prochains webinars et nos actualités !
Import des sources applicatives
La plateforme Snowflake est prête à accueillir les données. Pour cela, nous allons utiliser l’ETL Talend. Une fois que nous avons créé les connexions à nos fichiers sources sur Talend, nous pouvons alors créer une connexion Snowflake qui servira de sortie aux tables transformées. Sur Talend, on doit donc configurer notre compte, utilisateur, rôle, Virtual Warehouse et base de données que nous allons utiliser sur le connecteur natif Snowflake disponible :

On réalise à partir des connexions nos jobs permettant la transformation des données, la création des tables sur Snowflake et le peuplement de celles-ci.
Nous devons maintenant passer à une étape qu’il ne faut pas négliger : il s’agit de la vérification des schémas des tables, des contraintes et de l’importation des données sur Snowflake. On remarque au travers de cette étape que les clés étrangères n’ont pas été pris en compte dans la déclaration des tables. Les contraintes d’unicité et de référence ne sont pas supportées par Snowflake mais uniquement déclarables afin de laisser une liberté totale à l’utilisateur.
Administration sur Snowflake
Maintenant nous avons à notre disposition un utilisateur administrateur qui a accès à toutes les données, mais aussi la possibilité de créer des objets. On crée aussi un autre utilisateur qui lui pourra uniquement voir les données qui composent les tables créées précédemment. Cependant, on ne peut pas attribuer des privilèges d’accès à un utilisateur directement, il faut pour permettre cela passer par un rôle que nous attribuons à l’utilisateur crée précédemment :

On a ensuite donné le droit d’usage au Virtual Warehouse dédié pour réaliser les rapports Power BI au rôle créé, ainsi que le droit d’usage sur la database et le schéma public.
Reporting
Il existe sur le logiciel un connecteur natif Snowflake qui facilite grandement la connexion entre les deux :

Une fois la connexion mise en place et les tables nécessaires choisies, nous avons sur Power BI un choix pour le type de connexion aux données. Il est fortement recommandé de choisir le mode « importer les données » pour des raisons économiques, si aucun problème de sécurité des données ou de volumétrie s’impose.
Nous avons donc maintenant un outil de BI qui interroge notre data Warehouse qui est alimenté en données via des flux ETL connectés aux sources applicatives.
CONCLUSION DE L’EXPERT
Snowflake se positionne facilement dans une chaine décisionnelle et les nombreux connecteurs avec les technologies du marché facilite son utilisation. Ce SaaS se distingue par sa rapidité et sa facilité d’utilisation et permet aux utilisateurs d’importer tout type de données structurées, semi-structurées ou non structurée.
Dans un prochain article, nous parlerons de la mise en place d’une chaine décisionnelle qui permet de suivre les recommandations de l’éditeur en utilisant Snowflake comme ODS et Data-Warehouse ainsi que la mise en place de flux ELT entre les deux.




