Contexte de gouvernance de données
Selon une approximation publiée dans le Digital Economy Compass 2019 de Statia, le volume de données numériques générées mondialement est passé de 2 zettaoctets à plus de 47 zettaoctets en une décennie soit une augmentation par un facteur 20. Toutefois ce chiffre n’est rien comparé à l’estimation pour l’horizon 2030 qui prévoit un volume de données généré de plus de 2 142 zettaoctets.
Ces données alimentent des systèmes d’aide à la décision qui deviennent de plus en plus complexes. Avec une grande multiplicité des sources de données et des opérations de transformation, les bases de données peuvent rapidement devenir denses empêchant toute visibilité sur les données.
Ces systèmes assurent un traitement de toutes les données afin de générer des indicateurs clés de performance et des indicateurs clé de business. De ce fait, les indicateurs doivent être précis, fiables et indiscutables. Le processus qui permet leur calcul doit pouvoir être retracé et audité. Ces systèmes se sont vus adaptés au traitement de cette quantité massive de données afin de les transformer en modèles et tendance.
Cette adaptation peut conduire à adopter différentes technologies qui produisent des données dans différents formats avec des volumétries variables. Il peut s’agir de base de données, de CRM ou encore des fichiers plats contenant des données détaillées. Ces éléments doivent fonctionner en toute transparence afin de créer un environnement de décision efficace.
Les données affichées dans les outils de rapports business intelligence sont différentes de leur état et valeur initiaux. Ainsi, déterminer quelles données étaient dans quel système, et quel système détient les données sources, est un défi.
Pour illustrer cela, imaginez que vous remettez en question la valeur d’un indicateur clé de performance.
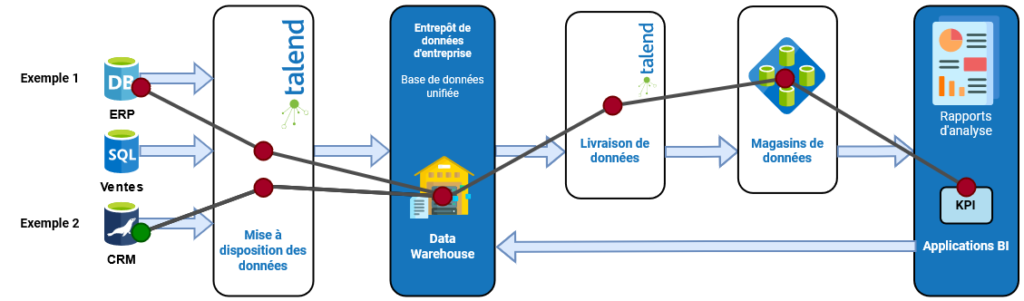
Dans le premier exemple, les données sources sont incorrectes (pastille rouge). Par conséquent, les valeurs utilisées dans le KPI, ou les valeurs du KPI, sont également incorrectes. Dans le second exemple, les données sources sont correctes (pastille verte), mais à un moment donné, le processus de transformation est défectueux.
Avec autant d’éléments à prendre en compte, retracer une empreinte numérique jusqu’à ses origines peut être difficile, voire impossible sans les moyens techniques appropriés. Certaines entreprises peuvent se référer à un document de cartographie, tandis que d’autres peuvent choisir d’analyser tous les scripts ou jobs de transformation. Ces deux méthodes peuvent être longues et fastidieuses.
Talend Data Catalog comprend des caractéristiques essentielles du catalogage de données, qui sont utilisées pour créer un catalogue central de données fiables sur lesquelles les membres d’une équipe peuvent collaborer et partager.
Il peut automatiquement découvrir, profiler, organiser et documenter des métadonnées, et les rendre facilement consultable. Le catalogage de données utilise le profilage des données pour profiler toutes les tables ou fichiers dans une collecte de métadonnées, puis utilise des algorithmes analytiques pour recueillir des lignes d’échantillons pour fournir des statistiques, des modèles et d’autres informations.
C’est afin d’apporter une solution viable et peu couteuse en temps que Talend propose une approche innovante. Elle repose sur une méthodologie de codification du contenu des documents : les métadonnées. Comme celles-ci sont des données sur les données, il est possible de les utiliser pour contrôler et auditer à chaque étape du processus BI.
En effet, les métadonnées peuvent aider à décrire les informations du système source d’où provient un élément, les tables et les champs dont il a été extrait, la façon dont une colonne est calculée en tant qu’élément de base de données, le mode de calcul d’une colonne ainsi que la définition d’un élément dans un contexte métier… Talend Data Catalog (TDC) offre cette capacité et plus encore, car la gestion des métadonnées et le catalogage des données sont à la fois inclus et complémentaires aux fonctions de l’autre.
Architecture fonctionnelle de Talend Data Catalog
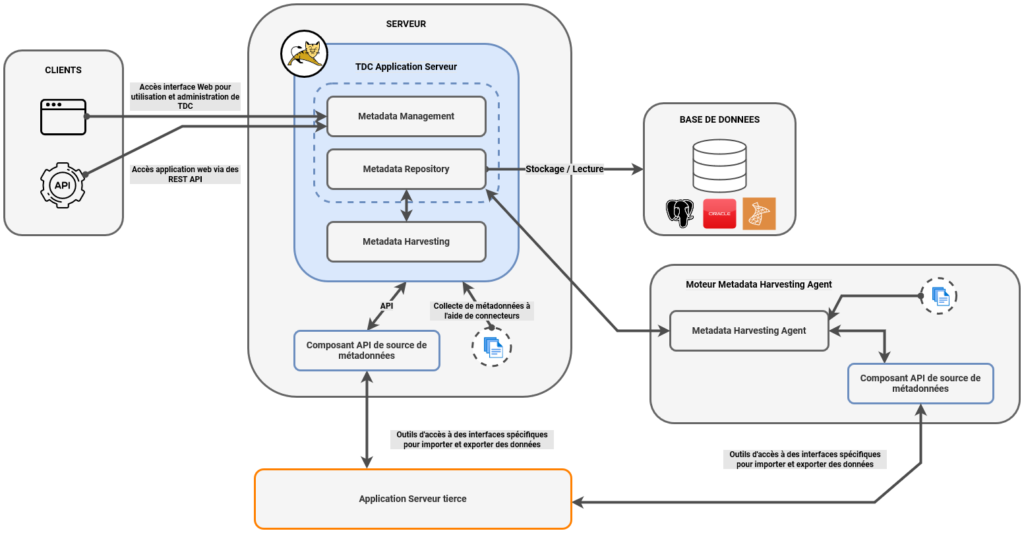
Talend Data Catalog présente différents blocs fonctionnels, le bloc Clients, le bloc Server, le bloc Base de données et facultativement un bloc de collecte de données à distance.
Le bloc CLIENTS représente l’interface Web Full HTML auquel l’utilisateur a accès. L’utilisateur peut y créer des modèles, importer des métadonnées, suivre le lignage des données, suivre l’impact de données, gérer le référentiel des métadonnées, créer des attributs personnalisés, ajouter de nouveaux types sémantiques à ceux déjà existant, concevoir une architecture d’entreprise, etc.
Le bloc SERVEUR comprend l’application Web Talend Data Catalog. Cette dernière utilise un serveur Apache Tomcat et s’exécute comme une application Web standard. Elle utilise Elasticsearch permettant une indexation et une recherche de données très rapide en utilisant un langage naturel.
L’application Web Talend Data Catalog comprend plusieurs applications dont Metadata Management qui est le cœur de cet outil. En effet, c’est à lui qu’on doit les fonctionnalités de de gestion de métadonnées, gouvernance de données et catalogage de données. Elle comprend également un référentiel (Metadata Repository) dans lequel sont stockées les métadonnées. On retrouve également le moteur de collecte de données Metadata Harvesting qui inclut plus de 250 connecteurs à différentes sources de données.
Le bloc BASE DE DONNEES contient la base de données dans laquelle sont stockées les métadonnées.
Enfin, si le client souhaite que le moteur de collecte de données soit installé sur une machine distante, cela est possible comme il est représenté sur la figure ci-dessous par le bloc Moteur Metadata Harvesting Agent.
Pourquoi Talend Data Catalog ?
Interface simplifiée
Organisation structurée des importations
A partir du menu OBJETS, vous pouvez :
- Effectuer des recherches filtrées ou travailler avec des listes plates de résultats de recherche.
- Choisir une activité récente.
- Utiliser le menu de navigation par catégorie (« Parcourir les catégories ») pour explorer rapidement les éléments de métadonnées de la configuration ou du référentiel, par catégorie et par type de métadonnée.
- Naviguer dans une structure hiérarchique unique de la configuration à partir du niveau de granularité le plus bas, sans s’arrêter au niveau du modèle en cliquant sur « Diagramme d’architecture ». Chaque élément du diagramme d’architecture peut être inspecté (avec un clic droit) en détail pour comprendre les processus d’intégration et de transformation des données qui sont liées entre elles.
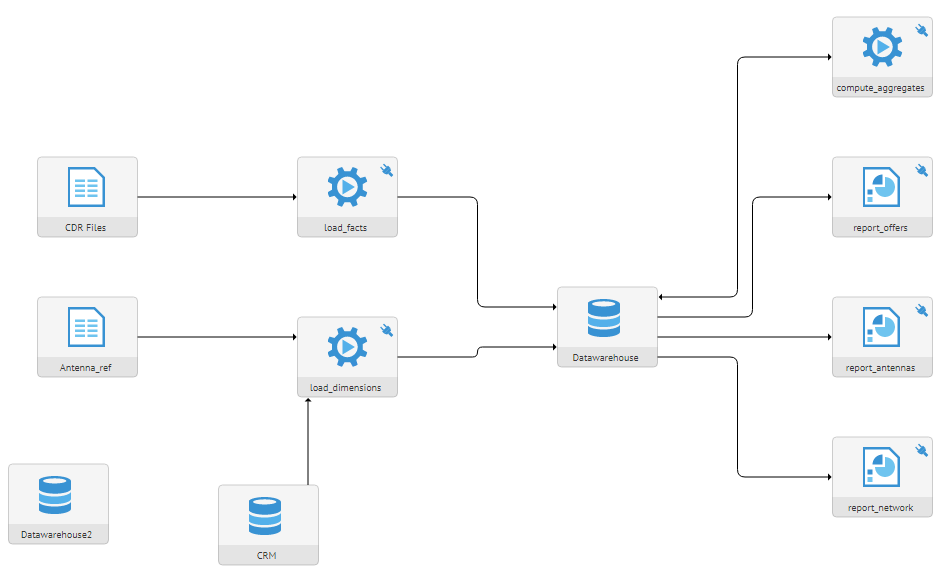
Collecte de métadonnées
La collecte de métadonnées peut se faire à partir de fichiers plats, de bases de données, d’univers, de rapports BI et bien d’autres. En effet Talend Data Catalog offre plus de 250 connecteurs à des sources différentes tels que Amazon Web Services, Databricks, IBM, Informatica, Microsoft (Azure, Power BO, SQL Server, …), la suite SAP ( HANA, BO, BW, …), Snowflake, et bien d’autres. Une seule installation de Talend Data Catalog constitue un seul point d’accès pour organiser des ensembles de données, gérer et rechercher des données spécifiques plus rapidement et comprendre ses métadonnées.
La première étape de la collecte avec Talend Data Catalog est d’enregistrer les sources de données à partir des accès métadonnées. Considérez Talend Data Catalog comme un registre d’atouts (ces atouts sont les données). Il enregistre les informations techniques sur le moyen d’accéder aux données et aux métadonnées en se basant sur la gestion de la qualité de données.
Talend Data Catalog ne stocke pas les données en tant que telles. Lorsque vous créez un nouveau modèle, vous devez spécifier un nom de modèle et une brève description. Un modèle est un plus petit élément dans la configuration (votre projet) et peut être une base de données, un Job ETL, ou encore un rapport.
Tous les éléments de métadonnées peuvent être collectés en utilisant les ponts de Talend Data Catalog. Lorsque vous collectez des métadonnées l’application serveur de Talend Data Catalog envoie les requêtes de l’utilisateur à l’application « Metadata Harvesting » afin de collecter les enregistrements de métadonnées à partir de la source de données. Cette requête est d’abord prise en compte par le pont de Talend Data Catalog afin d’accorder l’accès et d’établir les protocoles pour permettre une connexion à l’application source.
Le composant « Metadata API » déploie ensuite la requête en utilisant des objets personnalisés pour l’entreprise. Le composant API transfert la requête à une application serveur tierce afin d’établir un lien entre les ensembles de données et importe la source de données demandée. D’autres ressources peuvent avoir été recueillies au cours de ce processus.
Les métadonnées collectées sont ensuite récupérées par le composant API puis traitées par l’application « Metadata Harvesting » où elles sont personnalisées et transformées en information significatives selon les besoins de votre entreprise. Les métadonnées collectées sont ensuite mises à disposition par le référentiel de métadonnées et stockées localement sur une base de données où les utilisateurs peuvent y avoir accès pour de la gestion de métadonnées, la gouvernance de donnée ou encore le catalogage de données.
Lorsqu’il n’y a aucun pont Talend Data Catalog dédié, les métadonnées peuvent être collectées en utilisant un agent de « Metadata Harvesting » à distance installé sur un serveur séparé. Vous pouvez installer des serveurs de collecte de données dans vos locaux alors qu’une application serveur Talend Data Catalog peut être installée dans le cloud lorsque vous avez besoin de collecter des métadonnées localement, et que votre cloud n’est pas accessible.
Profilage et échantillonnage de données
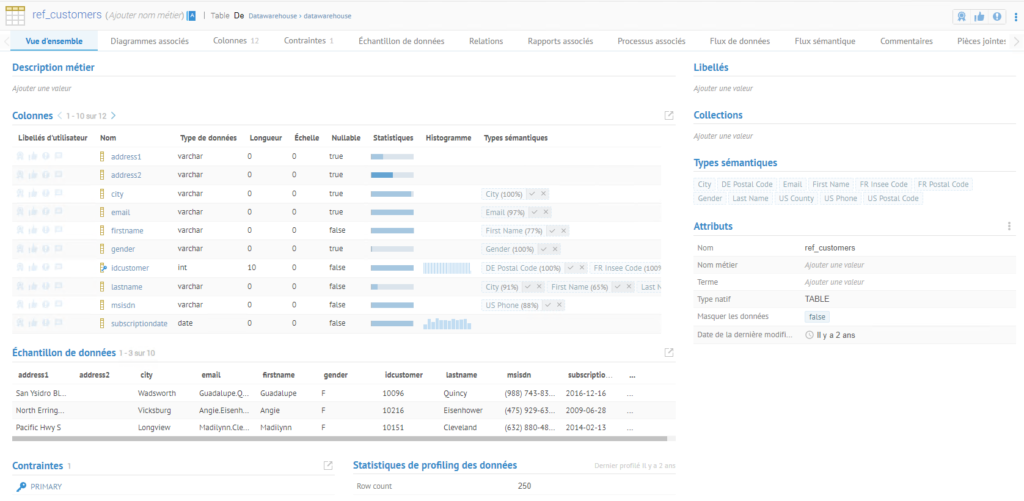
Talend Data Catalog peut échantillonner et profiler une large quantité de données en une seule fois. Il n’y a pas de limite à la quantité de données qui peuvent être échantillonnées ou profilées. Toutefois une quantité massive de données peut prendre un temps plus important pour être traitée en fonction du nombre de lignes. Il est recommandé d’indiquer un plus petit nombre de lignes (100 ou moins) pour permettre une meilleure évaluation de la qualité de données. Les informations de profilage et d’échantillonnage sont directement disponibles dans la vue d’ensemble de l’objet.
Le profilage de données permet de déterminer la légitimité et la qualité des données durant la phase de collecte car elle parcourt toutes les tables ou les fichiers d’une source de données afin de rechercher des données pertinentes et capturer des échantillons de lignes.
Lorsque le profilage de données est activé, vous pouvez planifier ce dernier afin qu’il soit exécuté périodiquement et mettre en place des limitations basées sur une durée maximale ou une quantité de données capturée. Toutefois, dans plusieurs cas, lorsqu’on collecte une quantité importante de métadonnées, les données ne sont pas analysées efficacement.
Le meilleur moyen de déterminer ce à quoi doivent ressembler les métadonnées est de faire un échantillonnage. Cette opération permet de récupérer des données basées sur le nombre de ligne spécifié durant la collecte. Ceci permet aux utilisateurs de consulter un échantillon de données directement depuis l’interface utilisateur afin de mieux définir ses métadonnées.
En fonction des droits d’accès aux sources de données, les utilisateurs peuvent ne pas être capables de consulter certaines données sensibles dans l’échantillon. Les données sensibles peuvent être protégées durant la collecte de données en utilisant l’option « Masquer les données » afin de détecter automatiquement le type sémantique ou manuellement lorsque vous exécuter profilage et échantillonnage.
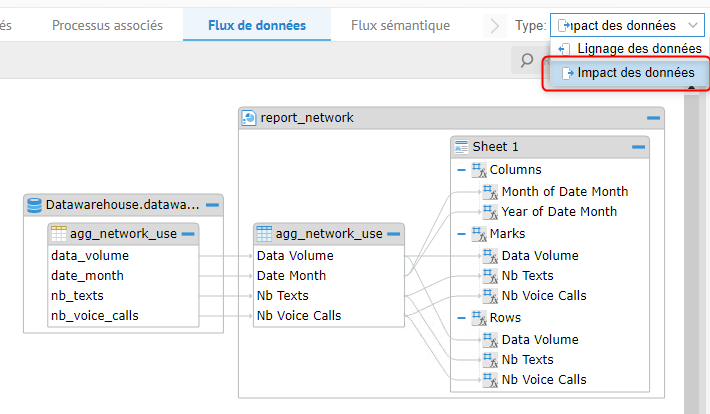
A partir de l’onglet Flux de données, l’origine des données dans le processus de business intelligence peut être retracée depuis une source brute jusqu’aux informations cibles du processus en utilisant à la fois l’impact et le lignage de données.
L’analyse du lignage de données (Data Lineage) retrace l’histoire complète du voyage des données. Il permet aux utilisateurs de comprendre d’où viennent les données, où elles existent et comment elles sont manipulées dans un processus d’analyse des données. Dans la figure ci-dessous, les données ont été extraites des fichiers sources de données et enregistrées dans le dossier de travail. Elles sont ensuite stockées dans des tables de base de données pour être analysées. L’utilisateur peut visualiser chaque composant de manière plus détaillée au niveau des attributs du flux de données.
Analyse de flux
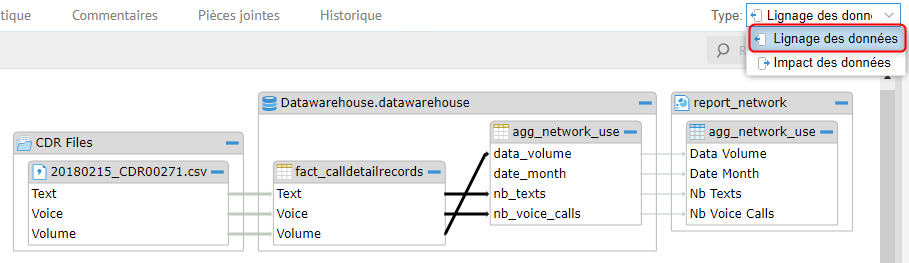
Les entreprises doivent définir et mettre en œuvre des politiques et des procédures pour la gestion opérationnelle et administrative quotidienne des systèmes. Les responsables de la gestion des données (Data Stewards) et les analystes peuvent utiliser l’analyse d’impact, qui est une inversion du lignage des données.
L’analyse d’impact des données permet de déterminer l’impact des modifications des données opérationnelles sur les outils de reporting du modèle afin d’identifier l’amélioration des processus métier, ainsi que les risques et la conformité.
CONCLUSION DE L’EXPERT
Tandis que la gestion de métadonnées fournit une vue holistique des métadonnées dans un cadre de travail, l’objectif du catalogage de données est d’obtenir le maximum de valeur pour le contenu du modèle.
La valeur ajoutée est obtenue en accélérant les délais de mise en conformité et l’amélioration de l’accessibilité à la donnée que ce soit pour les Data Lakes modernes hébergés dans le cloud ou les entrepôts de données basé sur une architecture d’entreprise classique.
La gestion de métadonnées et le catalogage des données sont complémentaires. Ces deux concepts sont inclus dans Talend Data Catalog.
Talend Data Catalog peut être utilisé pour l’analytique self-service tels que la collecte de connaissance sur vos données et faire respecter le contrôle. Il peut également être utilisé pour la mise en conformité et confidentialité des données (RGPD, PDPA, HIPAA, etc.). Un cas d’utilisation non négligeable est celui de la modernisation de l’informatique et la gestion du changement notamment l’analyse du changement et la migration ainsi que l’audit de données. Enfin, aujourd’hui on ne peut pas parler de données sans citer le marché des données et la monétisation de celles-ci. Talend Data Catalog peut vous aider à gouverner vos données pour en faire une ressource génératrice de revenue.
Nous sommes désormais partenaire Gold Talend afin de vous assurer le meilleur niveau d’expertise sur les différents outils de la plateforme.



